







リアル写真と判別不能なレベルの偽画像をAIが生成可能になるGANs向けアーキテクチャをNVIDIAが作成

NVIDIAの研究者たちが、敵対的生成ネットワーク(GANs)のための新しいスタイルベースのジェネレーターアーキテクチャを提案する論文を公開しました。このアーキテクチャは、教師なし分類における高レベルの属性(例えば、人の顔を学習させた場合のポーズやアイデンティティ)や、生成された画像(例えば髪の毛)の確率的変化などを使いやすいものにし、スケール特有の合成制御を可能にするためのものだそうです。
[1812.04948] A Style-Based Generator Architecture for Generative Adversarial Networks
https://arxiv.org/abs/1812.04948
NVIDIAが提案する新しいスタイルベースのジェネレーターアーキテクチャを用いることでどのようなものが生成できるのかは、以下のムービーを見れば一発でわかります。
A Style-Based Generator Architecture for Generative Adversarial Networks - YouTube
GANsは新しい画像から「実際の写真」を模倣する方法を学習することができます。しかし、これまでのアプローチでは、GANsで画像を生成するには非常に限定された制御が必要でした。
そこで、NVIDIAの研究者たちは新しく「人間の監視なしでも自動で画像の異なる要素について学習できるジェネレーター」を提案しています。GANsの学習後、要素を好きなように組み合わせることが可能なため、多種多様な偽の画像が生成可能になるとのこと。

というわけで、このムービーで表示される写真は基本的にNVIDIAの新しいスタイルベースのジェネレーターアーキテクチャが生成した「偽の顔写真」です。
以下の画像は上段に並んでいる写真(Source A)が性別・年齢・髪の長さ・眼鏡・ポーズの基となっており、下段左端の写真(Source B)はその他の要素の基となっています。その他の部分にある写真が、Source AおよびBを基にジェネレーターが生成した「偽の顔写真」です。

Source Bの写真を変更すると、ジェネレーターが生成する顔写真が一気に変わりますが、Source Aがベースとなっている性別・年齢・髪の長さ・眼鏡・ポーズは変更されません。


Source Bの写真が男性に変わっても問題なし。


Source Bの写真が子どもでもその特徴を生成画像が反映していることがよくわかります。


「我々の開発したジェネレーターは、画像を『スタイル』のコレクションとして考えています。各スタイルは特定のスケールでエフェクトをコントロールします」とのこと。

スタイルは以下のように分類されています。
Coarse styles(粗いスタイル):ポーズ、髪型、顔の形
Middle styles(中間のスタイル):顔の特徴、目
Fine styles(細かいスタイル):色の概要
例えば以下の場合、左の縦に3枚並んでいるのはジェネレーターに入力された実際の写真。1番上の金髪の男の子の写真から粗いスタイル、真ん中の茶髪の女性から中間のスタイル、一番下の黒髪の女性から細かいスタイルを抽出しています。髪型や顔の輪郭などは1番上の男の子似で、髪の毛やくちびる、目の色は1番下の女性の写真から来ていることがわかります。そして、目・眉毛・口などの顔面の各パーツは見比べて見ると、確かに左の真ん中の女性の写真と瓜二つ。

ここで「粗いスタイル」の基となる写真を変更。「粗いスタイル」はポーズ、髪型、顔の形のベースとなるものなので、ジェネレーターが生成した画像は少年から女性に変化しています。

さらに変更するとこんな感じ。「中間のスタイル」および「細かいスタイル」は変わらないので、顔のパーツや色味は同じまま、さまざまな性別の顔写真が生成されます。


「中間のスタイル」の基となる写真を変更すると、輪郭や髪型は変わらないまま、顔のパーツだけがガラッとチェンジ。彫りの深い白人顔からアジア系ののっぺりとした顔に変身してしまいました。

「細かいスタイル」の基となる写真を変更すると、全体の色味が変わります。

さらに、NVIDIAのジェネレータは、ポーズやアイデンティティといった高レベルの属性から重要でない変化を「ノイズ」として自動的に分離することも可能です。

ノイズの定義は以下の通り。
Coarse noise(粗いノイズ):大きな髪の毛のカール
Fine noise(中間のノイズ):細かいディテール、質感
No noise(ノイズなし):特徴のない絵画のような見た目
ジェネレーターが生成した以下の画像のノイズを自由に変更します。

縦に並んだスライダーが各種ノイズの強度を示しており、以下の画像は「0.00」となっているのであらゆるノイズがない状態、つまりは絵画のような見た目状態です。
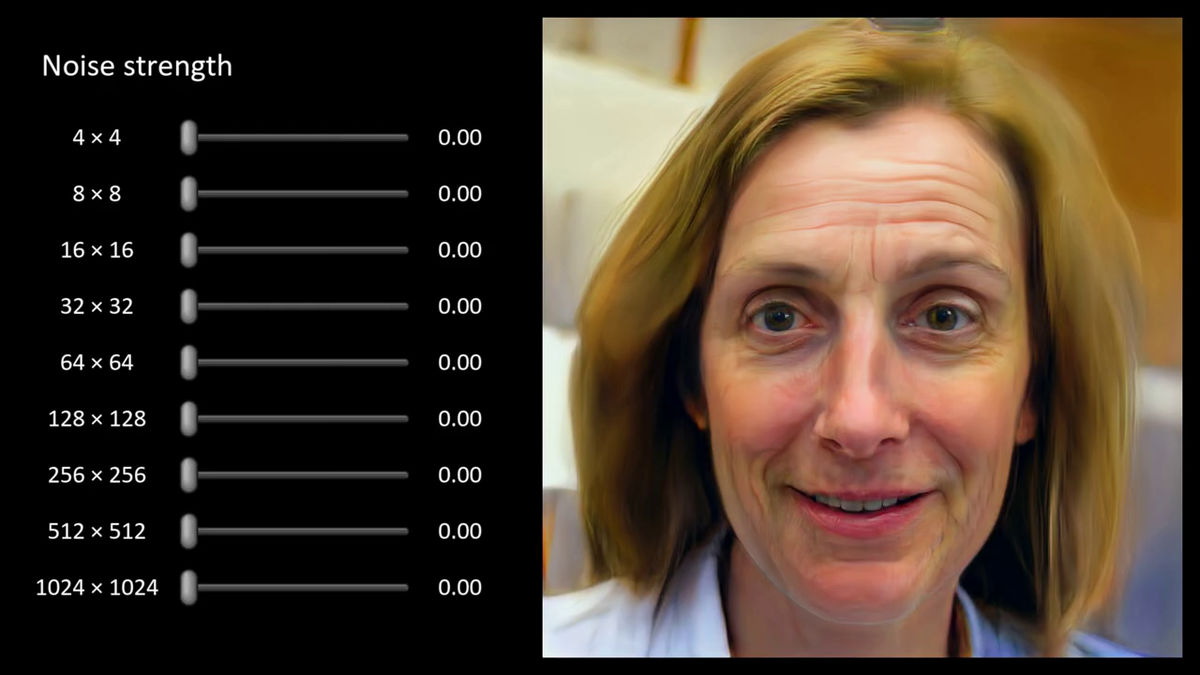
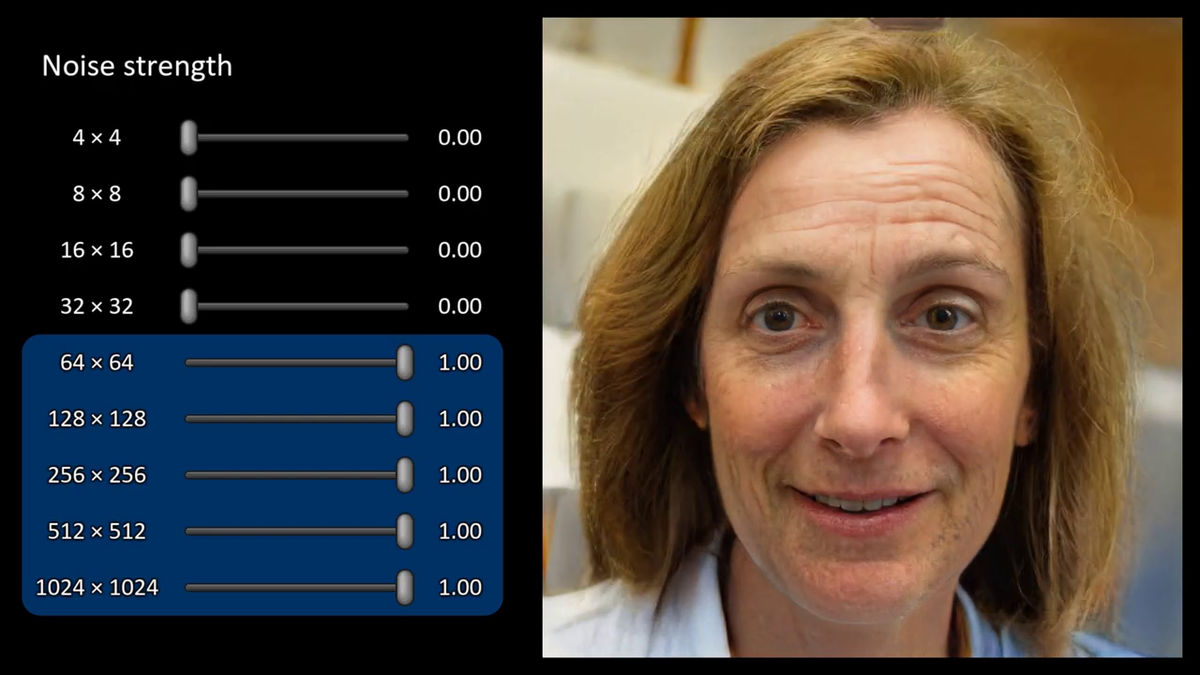
一部のノイズだけ変更すると、全体的にのっぺりとしていた画像に細かなシワや髪の毛の質感などが加わっていきます。

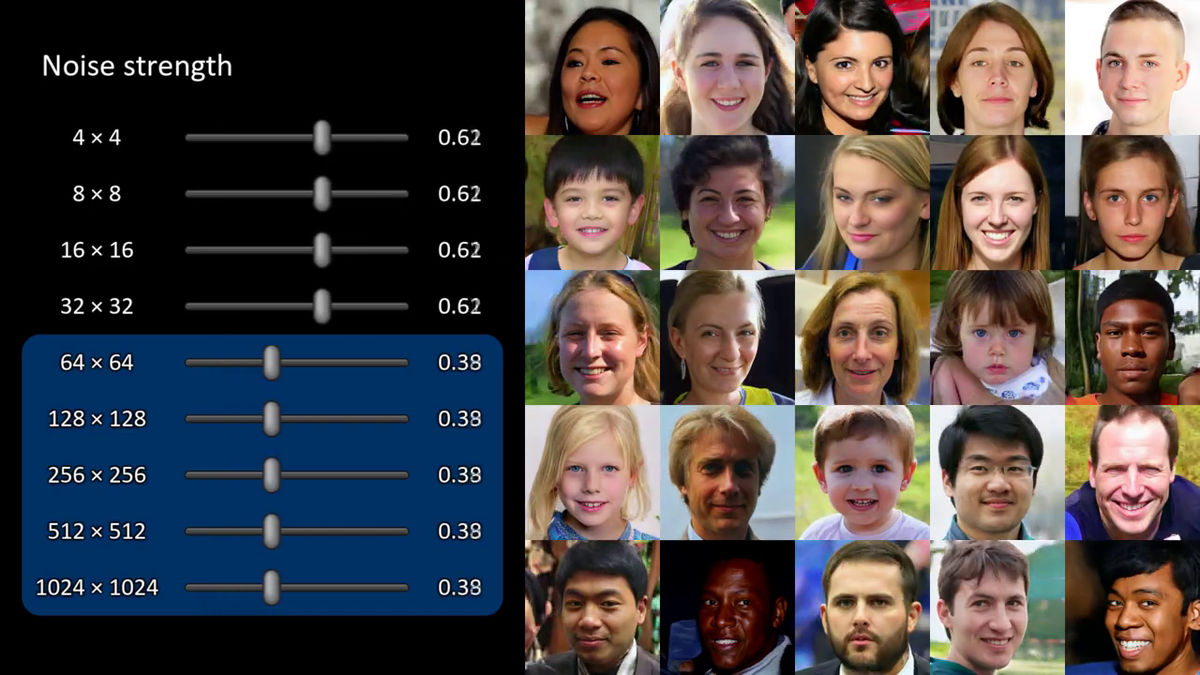
ジェネレーターが生成した複数枚の画像のノイズをまとめて変更するとこんな感じ。

ジェネレーターは生成される平均的な顔に対して、各スタイルの適用強度を自由に調整することも可能。

スタイルの強度により写真がどのように変化するかは以下の通り。
High strength(高い強度):最大の変動、いくつかの写真は壊れてしまう場合もあり
Low strength(低い強度):変動の低減、写真が壊れてしまわない範囲での調整
Negative strength(マイナスの強度):反対の顔
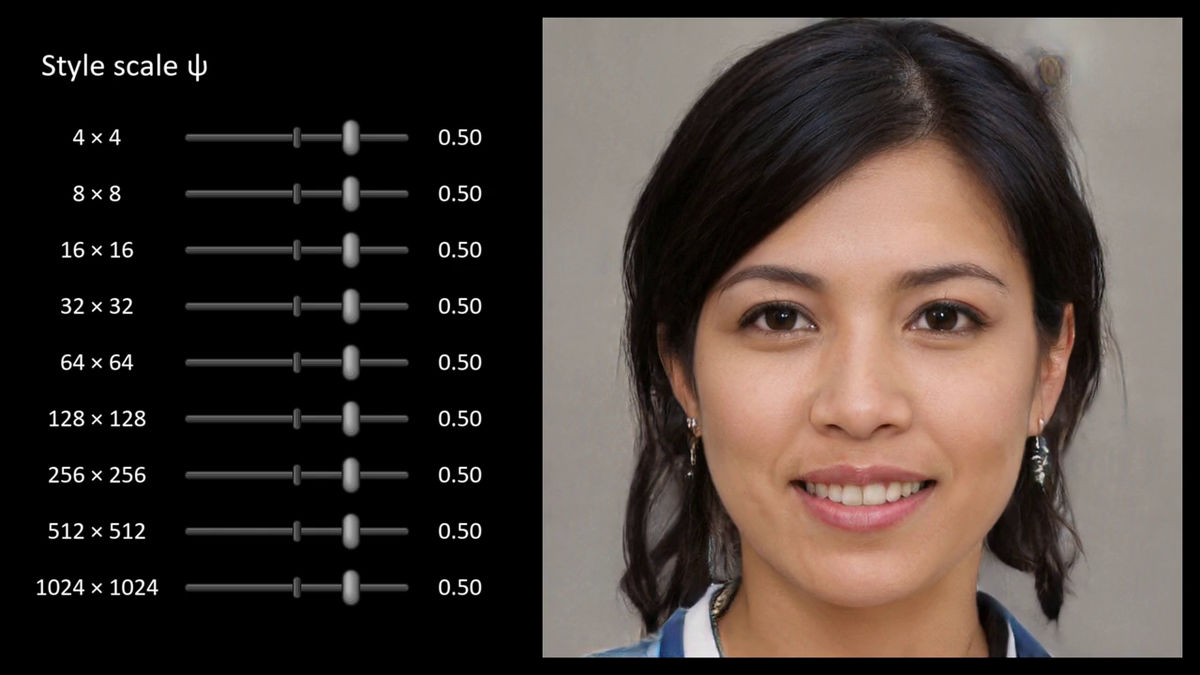
各種スタイルの強度が最大の時
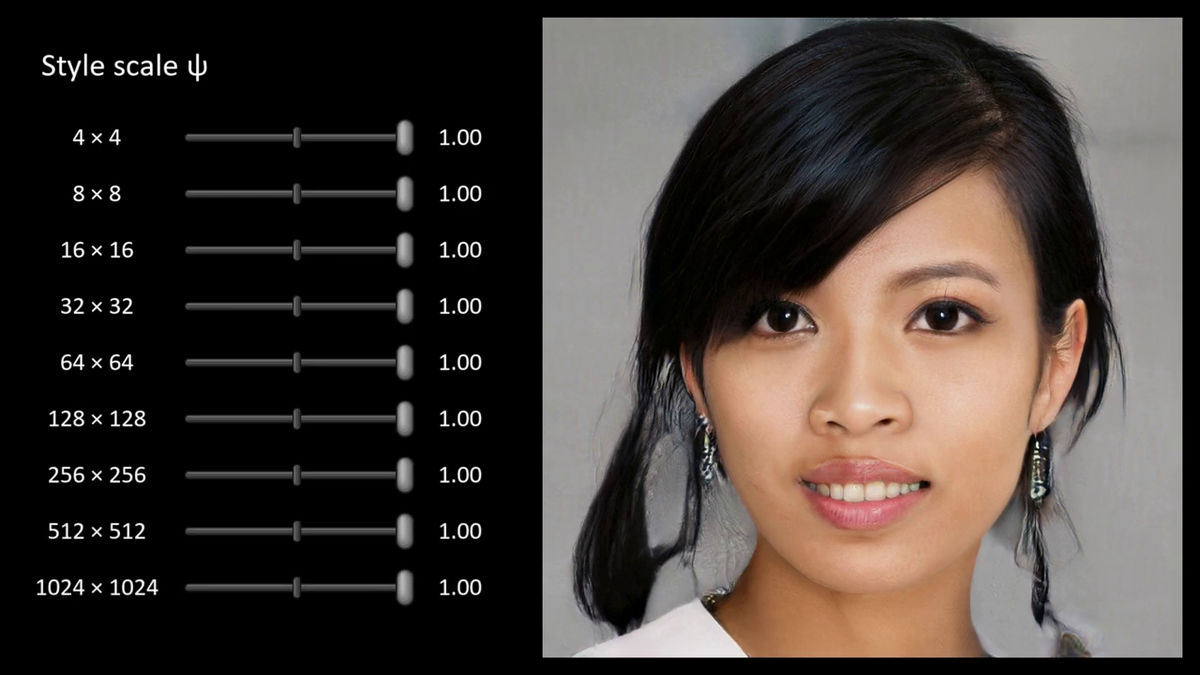
強度を少し減らした時
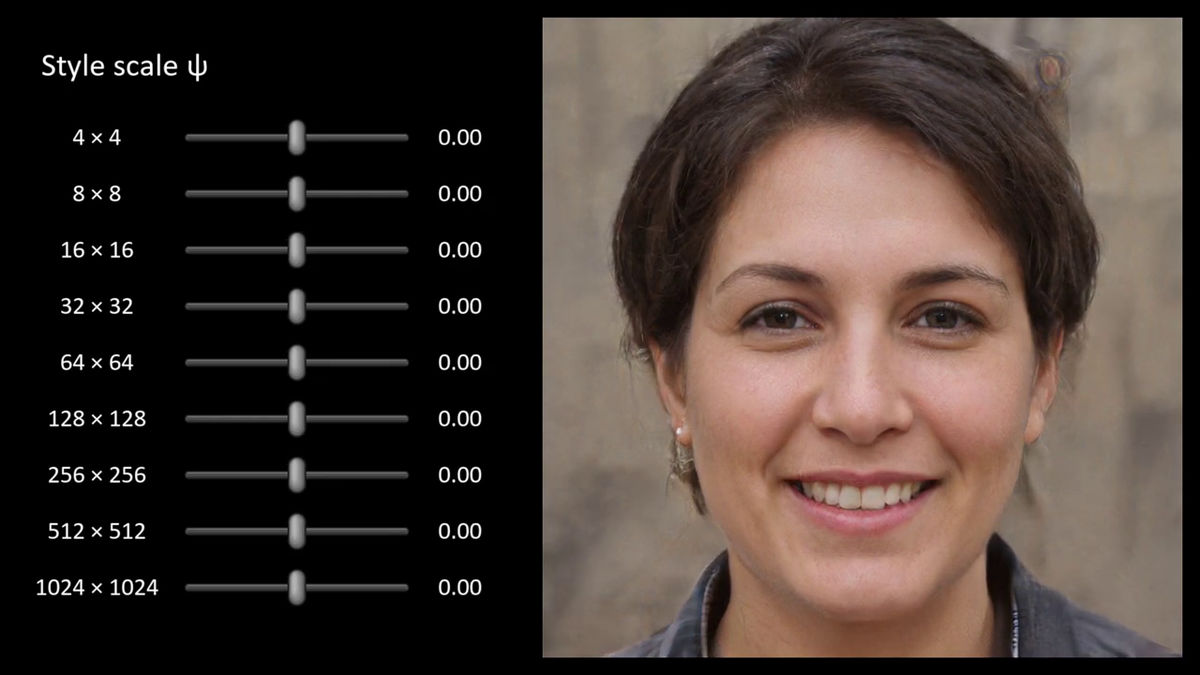
強度がゼロの時
マイナスの強度になると、性別が反転してしまいました。

各種スタイルの強度がゼロの時に表示されるのが、ジェネレーターが生成した平均的な顔
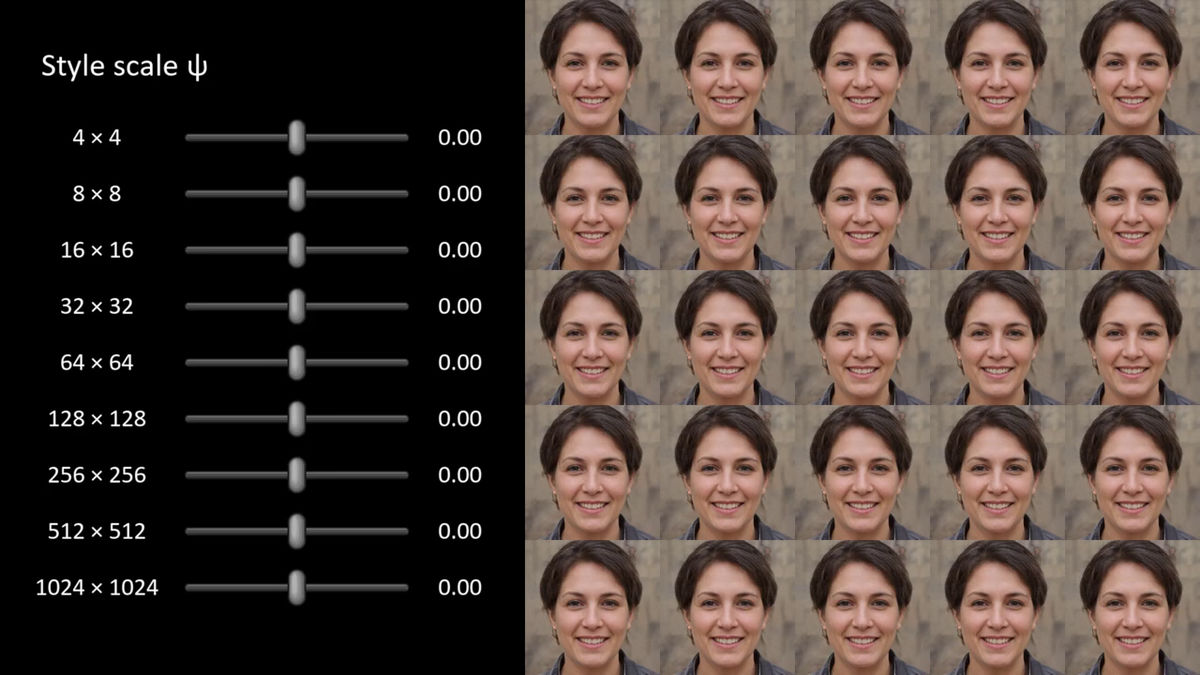
各スタイルの強度ごとに異なる顔に変化していきます。


「適度な強度を選択することで、バラつきが軽減されて良好な画像を生成することが可能になります」

ジェネレーターが生成した顔写真の作例は以下の通り。


データセットを変えれば、ジェネレーターに人間以外の画像を生成させることも可能です。自動車やベッドルーム、ネコなど。

「粗いスタイル」を変更すると、自動車やベッドの配置が変わり……



「中間のスタイル」を変更すると、車種やベッドの装飾が変わり……



「細かいスタイル」を変更すると、全体の色味がガラリと変わります。



・関連記事
クリックするだけで性別・年齢・髪型などを自然に変化させてリアルな顔写真を生成できる「TL-GAN」 - GIGAZINE
架空のアイドルを自動生成しまくる「アイドル生成AI」が誕生、どこかで見たことがあるようなないような顔が生成されまくり - GIGAZINE
AIが自動生成する「セレブっぽい写真」が実在するセレブっぽ過ぎて見分けがつかないレベル - GIGAZINE
簡単にAIが作成できる「AIメーカー」で画像判別AIを作成してみた - GIGAZINE
・関連コンテンツ







