







他人のiPhoneに「Hey Siri」と話しかけても反応しないのは機械学習によって誰が話しているのかを聞き分けているため

By Toshiyuki IMAI
「Hey Siri」はiPhone向かって「Hey Siri」と話しかけるだけでSiriを起動してくれ、ハンズフリーで音声入力を開始できる機能です。全員が同じフレーズを使用しているのですが、Siriが他人の声で起動してしまうことはあまりありません。その理由は「機械学習によって持ち主の声を認識する技術が使われている」ことにあるとAppleの公式ブログに書かれていました。
Personalized Hey Siri - Apple
https://machinelearning.apple.com/2018/04/16/personalized-hey-siri.html
「Siri」はiOS 5とともに2011年に発表され、それ以降のiPhoneに搭載されている音声認識機能です。2014年にはiPhoneに向かって「Hey Siri」と呼びかけるだけでSiriが起動し、その後の音声入力を受け付けてくれる機能も追加されました。iPhone 6までは充電中にしか使用できなかったHey Siri機能ですが、iPhone 6s以降は低電力のプロセッサを使用することでいつでもHey Siri機能が使用できるようになっています。
「Hey Siri、今日の天気は?」のように、Hey Siriという自然な呼びかけで音声入力を始められるのは良いのですが、開発当初はかなりの割合で「意図しないSiriの起動」が起きてしまっていたとのこと。この意図しない起動は「ユーザーが似たフレーズを言う」「他の人がHey Siriと言う」「他の人が似たフレーズを言う」という3つの状況で起きてしまいます。このうち、他人による意図しない起動を防ぐために話者認識の技術が使用されています。
話者認識とは、その名前の通り「誰が話しているのか」を特定する技術です。まずは認識したいユーザーにいくつかのフレーズを話してもらい、それを元にユーザーの声の統計モデルを作成します。そして実際に認識する際は、入力された音声をモデルと比較し、モデルに属する音声であるかどうかを判断します。
iPhoneでHey Siriを使用する際の初期設定ではあらかじめいくつかのフレーズを言うように指示されますが、その音声がモデル作成に使用されています。また、最初にモデルを登録する時以外にも、実際に使用する際の音声を使ってモデルをアップデートすることも行われています。ブログには、将来的にはHey Siriを使用する際の初期設定を不要にしたいと述べられています。
・Hey Siriシステムの概要
下図はHey Siriシステムの概要を表した図です。上半分が高レベルの図となっており、入力された音声はまず緑色の特徴抽出器で固定長のスピーカーベクトルに変換され、その後にモデル比較の段階へ入ります。特徴抽出機では、図の下半分に示されているように2段階の処理が行われます。第1段階で入力音声を固定長のベクトルに変換し、第2段階で話者固有の特性を強調するように変換します。そして、あらかじめ登録してあったモデルベクトルとの内積を計算し、その結果がしきい値を超えるとSiriが起動します。
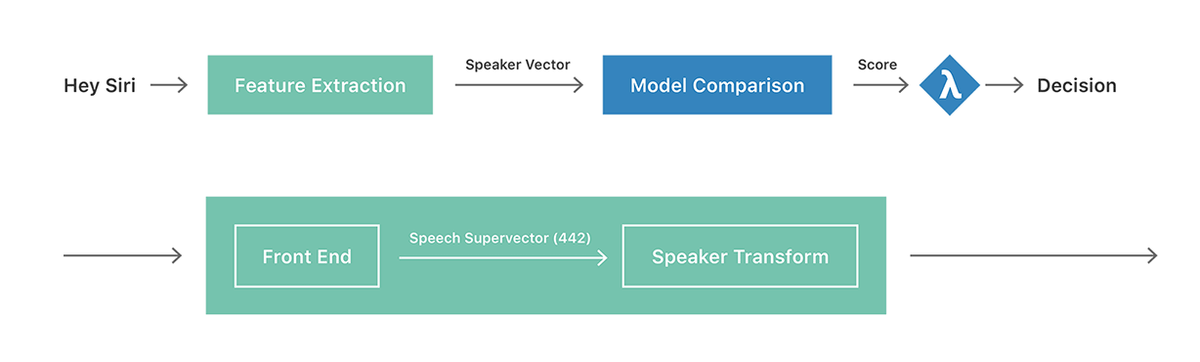
この話者認識の最も重要な部分は特徴抽出機の第2段階にある「話者変換」の部分で、この変換の目標は「同じ人の別のタイミングの声」の変動を最小にしつつ「別の人の声」との差異を明確にするというものです。Appleの初期のアプローチは、音の特徴量として13次元のメル周波数ケプストラム係数(MFCCs)と28変数の隠れマルコフモデル(HMM)を用いて「Hey Siri検出器」に音声ベクトルを入力するというもの。こうして生成された13×28=364次元のベクトルは、他のベクトルを連結したものなのでスーパーベクトルと呼ばれ、このスーパーベクトルが出力の音声ベクトルとなります。
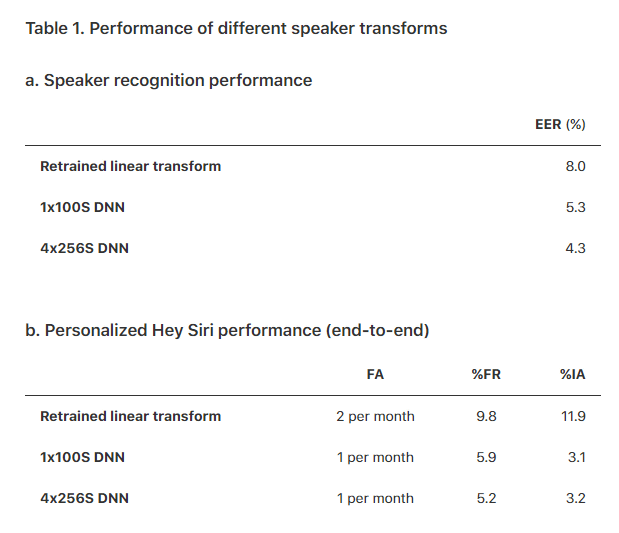
その後、線形判別分析を使用して「話者変換」がうまくいくように訓練することで誤認率が大幅に減少したとのこと。さらにディープニューラルネットワークの形で非線形識別技術を使用することで、さらによい変換を行えるようになったそうです。使用するメル周波数ケプストラム係数(MFCCs)の数を13から26にし、効果の薄かったHMMの最初の11変数を削除して17変数に減らし、出力を26×17=442次元の音声ベクトルにした上でニューラルネットワークに通します。ニューラルネットワークの構造は、まず入力ベクトルをシグモイド関数によって活性化を行う100ニューロンの隠れ層(1×100S)に通し、その出力を線形関数による活性化を行う100ニューロンの層に通し、最後にSoftmax層を通して出力を確率表現に変換するというもの。このニューラルネットワークをトレーニングした後、実際に「話者変換」を行う際は最後のSoftmax層を取り除いてスピーカーベクトルとして出力します。

さらに最適化を繰り返し行い、最終的に4つの256ニューロンからなるシグモイド層(4×256S)と1つの100ニューロンの線形層から構成されるニューラルネットワークが最もよい結果を残したとのこと。その結果、「本人が『Hey Siri』と言っているのに誤って他人と識別してしまうFalse Reject(FR)」と「他人の『Hey Siri』に反応してしまうImposter Accepts(IA)」の比率が一致するポイントであるEqual Error Rate(EER)は4.3%まで減らせています。
ニューラルネットワークによって話者認識機能は大幅に改善されていますが、依然として反響する部屋やうるさい環境では十分なパフォーマンスを発揮できていません。Siriの開発チームは厳しい環境での劣化を把握して定量化することに焦点を当てているとのこと。すでにノイズやエコーをかけたテストデータを用いてトレーニングすることで一定の成果を挙げているとのことです。
また、Hey Siri機能の目的は「Siriを起動すること」です。ここまではトリガーフレーズであるHey Siriの話者を認識することについて説明してきましたが、「Hey Siri」以外の言葉でも話者を特定できれば「~~~、今日の天気は?」というようにHey Siriという発話句がなくてもSiriに話しかけることもできます。開発チームの次の論文では、長・短期記憶ユニットを使用して特定の言葉の場合と非特定の言葉の場合の両方で可変長の音声から話者の情報を集約するという研究を行っています。Siri開発チームの成果は「Hey Siri」の話者認識を使用することでパフォーマンスが大幅に改善できることを示しています。
・関連記事
Siriと「ザ・ロック」ことドウェイン・ジョンソンがまさかのコラボを果たす「Rock X Siri: Dominate the Day」がYouTubeで公開へ - GIGAZINE
人間に聞こえない音を巧みに操りSiriなどの音声アシスタントをハッキングする「ドルフィン・アタック」とは? - GIGAZINE
「死体をどこに隠したらいい?」とSiriに隠し場所を尋ねた殺人事件が発生 - GIGAZINE
iPhoneのSiriはトロンボーンの音を文字に変換する恐るべき能力を備えていることが判明 - GIGAZINE
AppleのSiri関連雇用が過去最高に、Siriのアップグレードが目的か - GIGAZINE
4歳の男の子が意識不明の母親の親指でiPhoneを使いSiriで緊急通報して命を助ける、音声記録も公開 - GIGAZINE
・関連コンテンツ







