







「複数の音が混ざった音声から特定の1人の声だけを抜き出す技術」をディープラーニングを用いてGoogleが開発
多くの人が集うパーティー会場のような、たくさんの人が談笑している中でも自分の名前や興味のある話を自然と聞き取ることができる現象は「カクテルパーティー効果」と呼ばれ、人間が持つ能力「選択的注意」の代表例とされています。Googleの研究者は、ディープラーニングを用いることでコンピューターに自動で混ざり合った音声を分離する技術を習得させて、コンピューターにカクテルパーティー効果を身に付けさせることに成功しました。
[1804.03619] Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
https://arxiv.org/abs/1804.03619
Research Blog: Looking to Listen: Audio-Visual Speech Separation
https://research.googleblog.com/2018/04/looking-to-listen-audio-visual-speech.html
人間は無意識のうちに複数の音を処理して、聞きたい音だけを選択的に聞くことが可能ですが、コンピューターにとっては難しい課題とされていました。Googleの研究者たちはディープラーニングを用いて、カクテルパーティー効果は他の人の声や背景の雑音などが混ざり合った混合音から、単一の音声信号を分離する視聴覚モデルを作り上げたとのこと。
Googleが作り上げたモデルでは、単一のオーディオトラックを持つムービーに映った複数の人の中から、「この人の声だけが聞きたい」という人の顔を選択することで、その人が発する言葉だけを強調して他の音を抑制することが可能です。この機能は大勢の聴衆がいる中でのスピーチ映像やムービー会議、補聴器の改善などで役立てることが可能と考えられており、幅広いアプリケーションに応用されるかもしれません。
「Looking to Listen」と名付けられたこの技術が、1つのムービーに対してどのように使われるのかは、以下のムービーを見るとわかります。
Looking to Listen: Stand-up
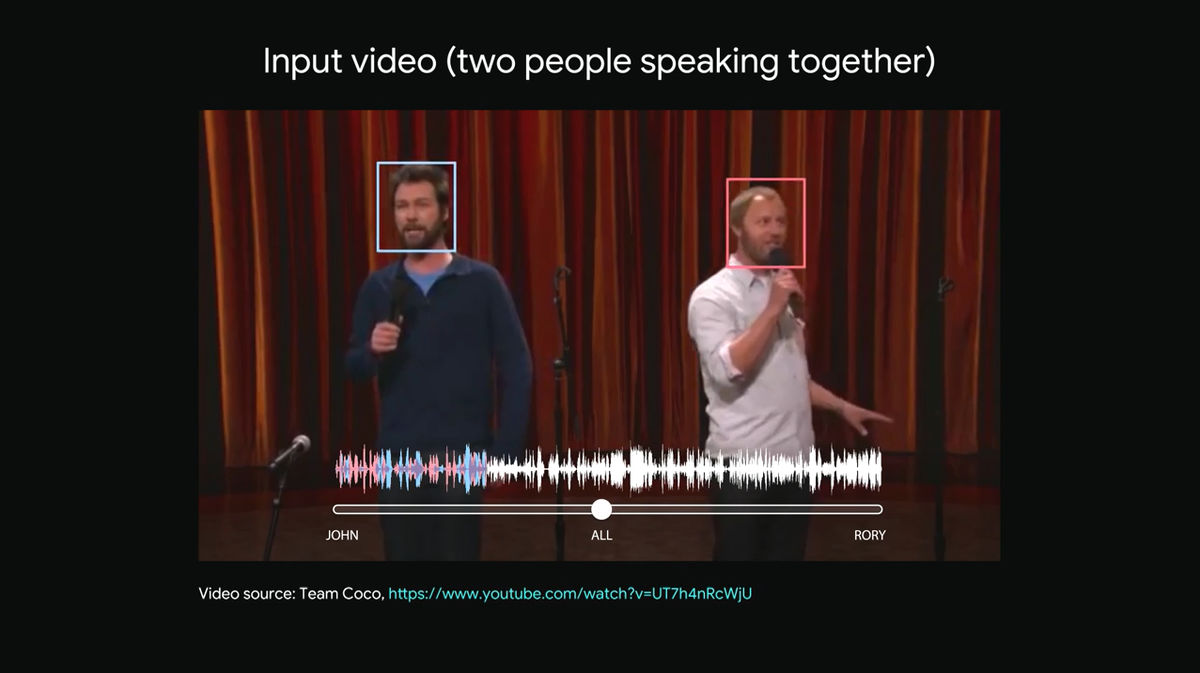
2人の人物がステージの上でしゃべっていますが、バラバラに全く別のことをしゃべっており、聴衆の笑い声や物音も気になるため何を言っているのかわかりません。

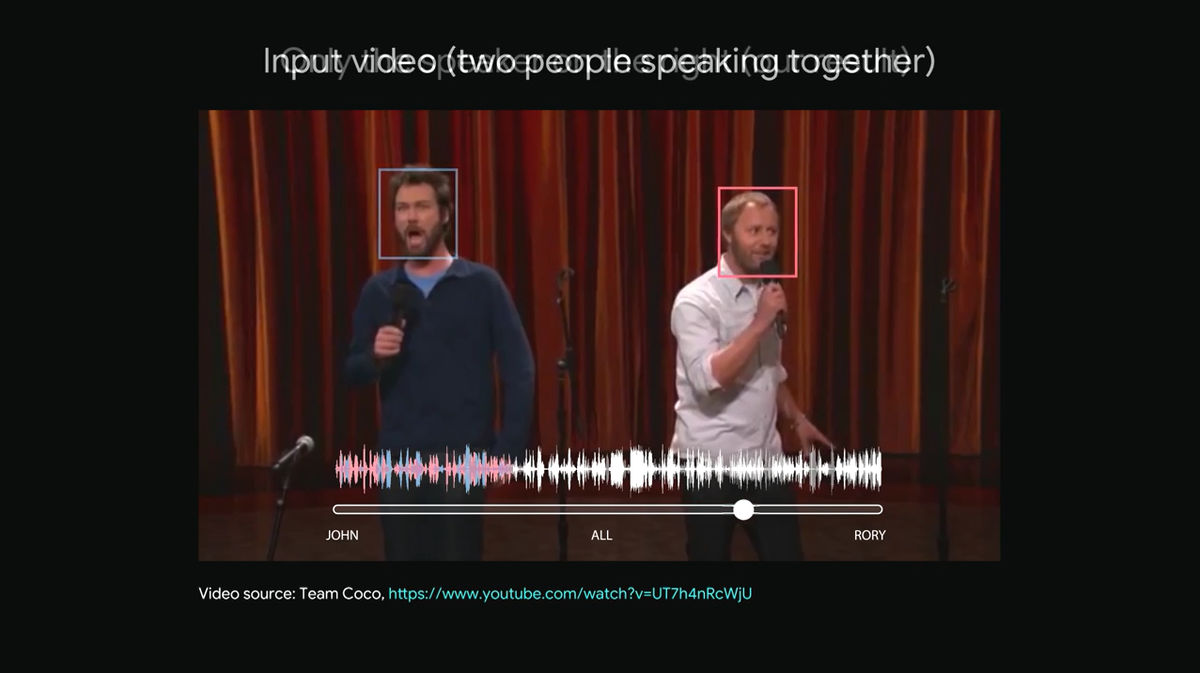
しゃべっている2人の男性の顔には四角く枠が付けられており、左側に立つ男性が水色、右側に立つ男性がピンク色です。下部の音を表す波形はそれぞれの男性がしゃべっている音声を表しており、水色の男性がしゃべった言葉(水色の波形)とピンク色の男性がしゃべった言葉(ピンク色の波形)が、ごちゃごちゃに混ざり合っていることがわかります。
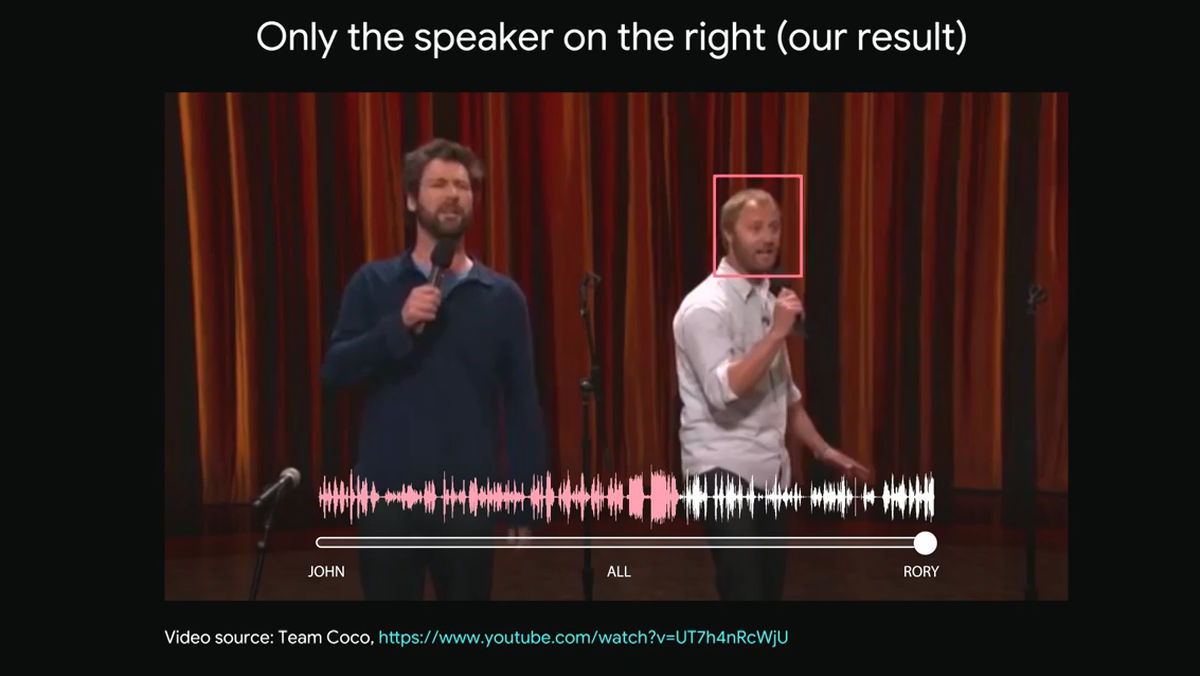
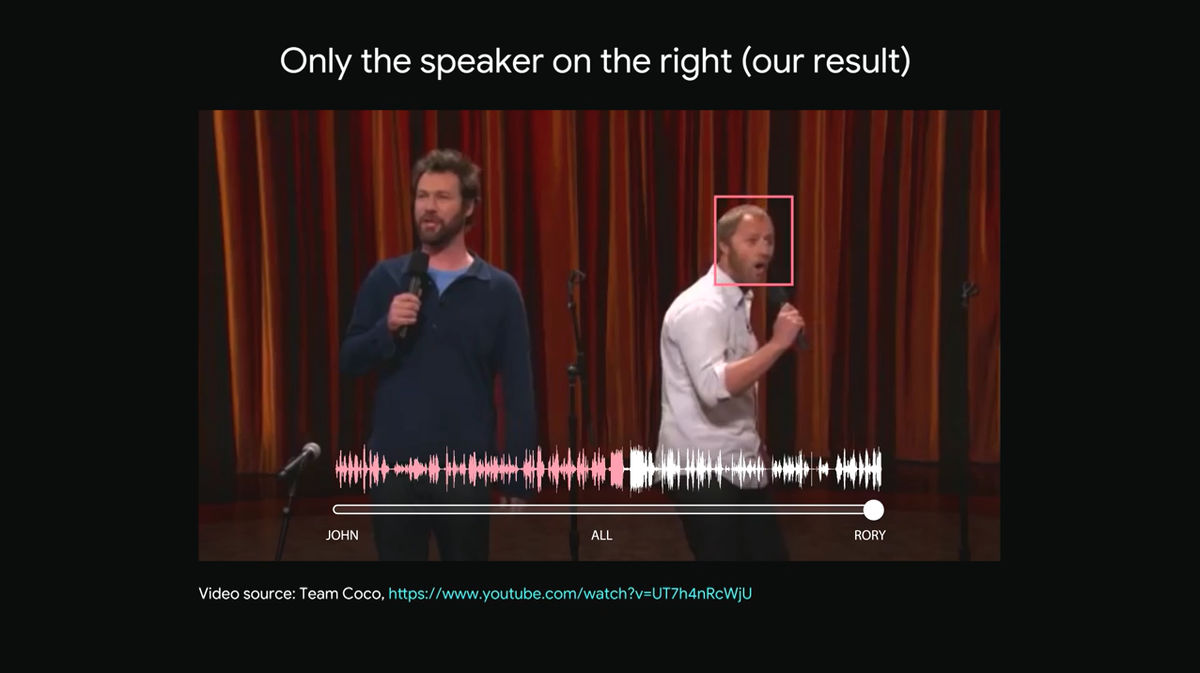
ここで下部のスライダーを右へ滑らせていくと……
右側に立つ男性のピンク色をした波形の声だけが聞き取れるようになります。
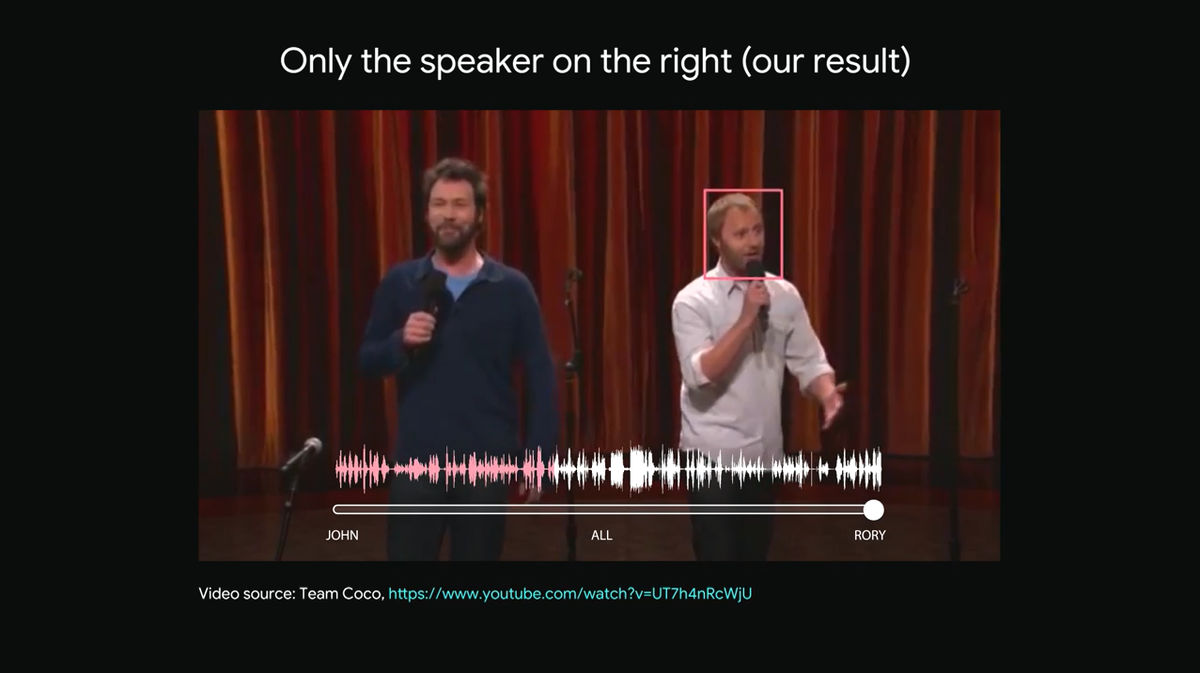
左側に立つ男性もかわらずにしゃべり続けているのが映像からわかりますが、人工知能が右側の男性の声だけを選択的に聞き取っているため、ほとんど左側の男性の声は聞こえません。
今度はスライダーを左に滑らせていきます。
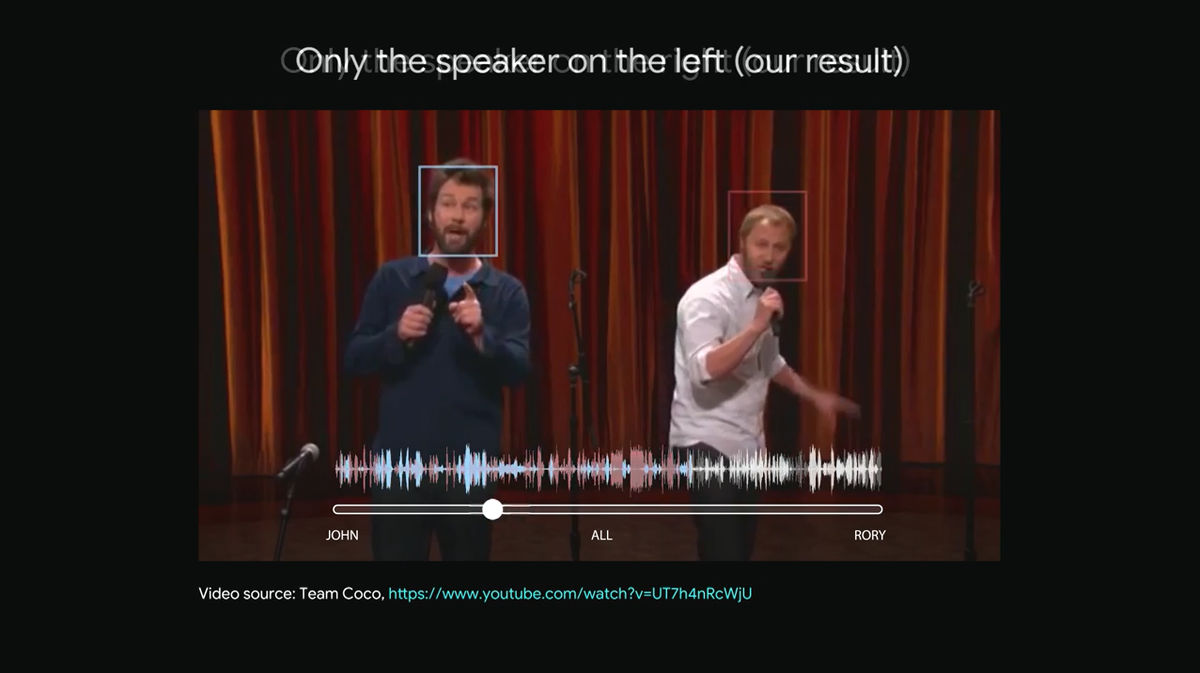
すると、左側の男性がしゃべる水色の波形で表された音声だけが、選択的に聞こえるようになりました。
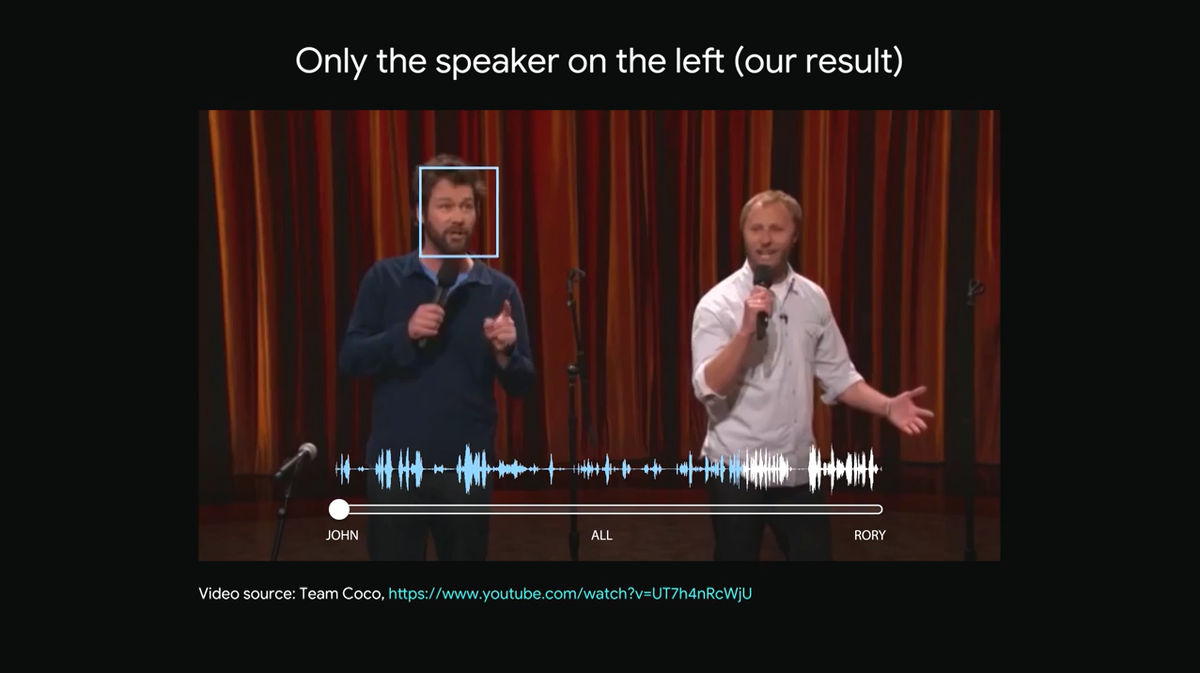
Googleが発表した「Looking to Listen」の技術で特徴的な点は、音声を分離するためにムービーの聴覚信号と視覚信号の両方を統合する点にあります。人の口の動きやしぐさはその人が話す声と相関があり、その人が話す声を特定することに役立ちます。聴覚信号のみを使用した音声分離技術に比べ、視覚信号を一緒に用いた場合は音声分離品質を大幅に向上させることが可能になるとのこと。
ディープラーニングの教材として、Googleの研究チームはYouTubeから10万もの講義や講演のムービーを収集し、その中から背景の雑音や他の人の話し声がなく、ムービーに発話者1人しか映っていない「クリーンな音声と映像」を約2000時間分抽出しました。これらのクリーンな音声と映像を複数合成して、研究チームは「人工のカクテルパーティー」を作成し、人工知能に学習を行わせました。その結果、選択した人物が話す声を強調し、関係のない音を抑制することが可能になったそうです。

なんと、同じ人物が同一のムービーに映って全く違うことを話している場合でも、視覚信号を用いた学習を行わせることで音声を分離することに成功しています。GoogleのCEOであるサンダー・ピチャイ氏のスピーチを合成した以下のムービーでは、同じ人物による発話が混在しているにもかかわらず、人工知能が選択的に音声を分離できていることがわかります。
Looking to Listen: Double Sundar
Googleは「Looking to Listen」の技術を使用した幅広いアプリケーションを想定しているとのことで、そのうち私たちの身近なところにも、「Looking to Listen」が応用されるしれません。
・関連記事
AIの発展とコンピューターに対する疑念を描いたドキュメンタリー「Do You Trust This Computer?」の予告編が公開中 - GIGAZINE
頭の中でつぶやいた「内言」を顔の筋肉から読み取って会話できるシステムをMITが開発 - GIGAZINE
MicrosoftのAIは会話の「間」を予測して、より自然なコミュニケーションを可能にする - GIGAZINE
AppleがGoogleの人工知能(AI)開発チーフをスカウト、Siriのアップグレードにも大きく影響する可能性 - GIGAZINE
AIを「新しい分野」で研究すべき時期が到来している - GIGAZINE
・関連コンテンツ







