画像のノイズを落としたり容量を小さくしたりするにはどのようなコードを書く必要があるのか?

手書きのメモをスキャンししたときにどうしても発生してしまうノイズを取り除くとともに、ファイルサイズも減らす方法を、スワースモア大学准教授のMatt Zuckerさんが具体的に公開しています。
Compressing and enhancing hand-written notes
https://mzucker.github.io/2016/09/20/noteshrink.html
Zuckerさんが持つクラスの中には教科書を使用せずに行うものもあり、そうした場合Zuckerさんは「学生書記官」を任命してノートを取ってもらい、スキャンしてアップロードするそうです。
例えば、以下の画像のようなページをスキャンする場合を考えてみます。この画像は300DPIでスキャンされており、約7.2MBのPNG形式で保存されています。それを画質85でJPGに変換すると約790KBになりますが、1ページで790KBというのは比較容量が大きめ。Zuckerさんの目標はページ当たり100KBとのこと。また、裏のページが透けて見えてしまっており、読む人の気を散らせてしまいます。

そこで、結果から先に表示すると、Zuckerさんが作成したプログラムで変換した画像が下のもの。このPNGファイルの容量は121KBで、ノイズを落としてきれいになるだけでなく容量の削減にも成功しています。

実際にZuckerさんが行った手順は以下の3つ。
・元のスキャン画像の背景色を特定する
・背景色との色の差を基準に色を分類する
・分類した色から代表的な少数の色を選択し、インデックス付きのカラーPNGに変換する
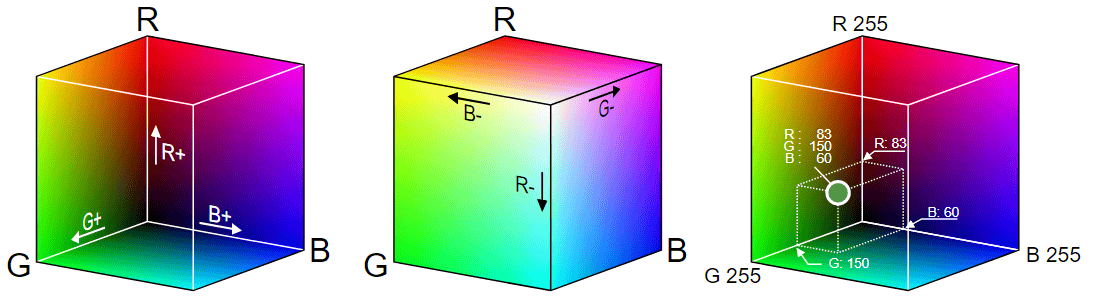
これらのステップの具体的な手順に入る前に、カラー画像がどのように保存されているかをおさらいしておくのが良いとのことです。人間は色を認識する3つのタイプの細胞を持っているため、赤色・緑色・青色を組み合わせることで任意の色を表現できます。RGBベクトル空間は連続ですが、デジタルデータとして保存する都合上量子化が必要になり、一般的には各色を8bitのデータで表します。8bitというのは2の8乗のことで、つまり各色の強さを256段階で表すということです。
・背景色を特定する
実際に背景色を特定していくにあたって、Zuckerさんは「スキャンした画像中にもっともよく現れている色」を背景色にするのが良さそうだと考えました。元のスキャン画像は縦横2081x2531で、合計526万7011ピクセルのデータですが、そのうち1万ピクセルをランダムに抜き出して調べたとのことです。

そして赤色・緑色・青色の明るさを合計した数値で並び替えると下の画像のようになります。ぱっと見では同じような白に見えた部分も、ピクセルごとに微妙に異なっていることがわかります。この画像で「一番出現した色」は1万ピクセルのうちたった226ピクセルしか占めていないので、確実というには心もとないです。

そこで、色ごとに8bitだった情報量を切り捨てて4bitにしたのが下の画像です。4bitにすることで「色の微妙な差」が切り捨てられ、結果として「一番出現した色」は1万ピクセルのうち3623ピクセルを占めるようになりました。画像の36%以上を占めている色なので、背景色と見なして良さそうです。

・色を分類する
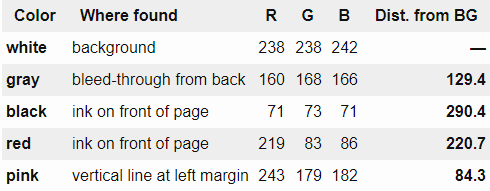
背景色が特定できたら、次に色を分類します。下の5色は左から「背景」「後ろのページから透けている文字」「黒いインクで書かれた文字」「赤いインクで書かれた文字」「左の縦線」です。

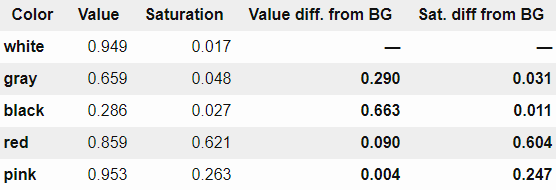
自然な発想として、RGB色空間でのユークリッド距離を計算して類似度を計算するという方法がありますが、下の表右端にあるとおり、透けている文字の消したい色である「gray」よりも残したい左の縦線の方が、背景色に似ていると判定されてしまいます。
そこで、ZuckerさんはRGB色空間ではなくHSV色空間を使用したとのこと。RGB立方体をHSV色空間に投影すると円筒状になり、この円筒は角度が色相(Hue)、中心軸から外側への距離は彩度(Saturation)、そして高さが色の全体的な明るさである明度(Value)を示しています。

再び先ほどの5色の値を調べてみると下の表のようになります。これを元に色がページの前にあるものなのか、後ろから透けてきたものなのかを判定します。今回Zuckerさんは「明度が背景から0.3以上異なる」または「彩度が背景から0.2以上異なる」ような色をページの前にあるものと判定したとのこと。こうして、必要な色だけ取り出すことができました。
・代表となる色を選択する
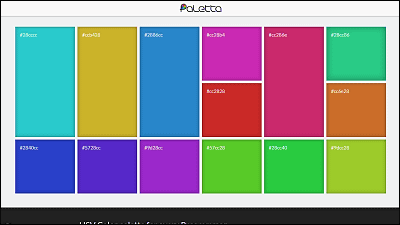
必要な色が出揃ったので、その必要な色のセットを視覚化してみます。
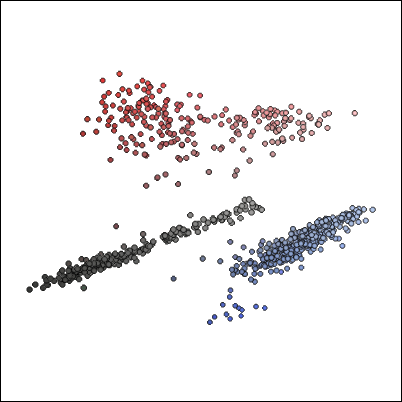
各色8bitで表されている合計24bitのセットの中から、8個の代表となる色を抜き出し、他の似たような色を集約して合計3bitのデータにしていきます。こうすることでファイルサイズを圧縮でき、また似たような色を同じ色にすることで見た目をまとめることができます。
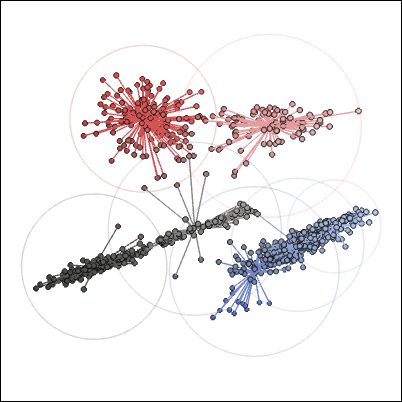
Zuckerさんは代表となる色を「k-meansクラスタリング」を使って求めたとのこと。これは各点から最も近い中心までの距離を最小にする中心の集合を求めるもので、先ほどと同様に視覚化してみると以下の画像のようになります。
また、抽出した代表色の強度を改めて0から255にスケールさせることで、最終パレットの鮮やかさやコントラストを改善できるとのこと。例えば下の画像のパレットが……

下の画像のように鮮明になります。

こうして、手書きのノートを少ない容量できれいに保存することができます。
他のデータを入力してみます。画像に応じてパラメータの調整が必要とのこと。また、左が入力データで右が出力データです。
上のノート画像のカラークラスタはこんな感じです。
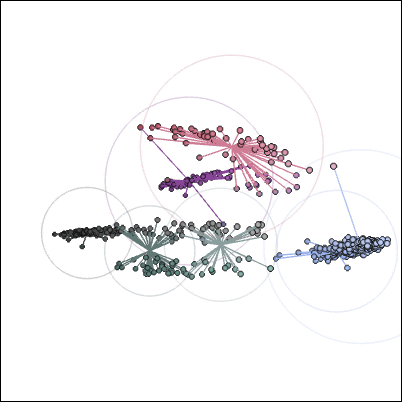
別のノートも格段に読みやすくなりました。
パラメータを調整すれば下の画像のような手書きメモも読みやすく鮮明にできます。

実際にZuckerさんが作成したPythonのコードはGitHubにアップロードされているため、誰でも確認できます。
・関連記事
データ分析や機械学習にバリバリ使える上にブラウザで使用できて環境構築不要のPython実行環境「Google Colaboratory」 - GIGAZINE
JPEG画像をロスレスで22%も圧縮できるオープンソースソフト「Lepton」をDropboxがリリース - GIGAZINE
粉砕され圧縮された木は鋼より強度のある材料となる - GIGAZINE
無料で超簡単に手元の画像からカラーパレットを作成できる「HD Rainbow」 - GIGAZINE
カラーチャートをグルグル動かして好みの配色を探せる「Color Supply」 - GIGAZINE
・関連コンテンツ