AIを訓練するためAmazonのクラウドソーシング経由で50万人が働いている

by Ricardo Diaz
AI(人工知能)がどれだけ優秀だとはいっても、まだまだ人間の方が効果的に処理できることは残されています。そういった仕事を細かく割り当てる場として、Amazonでは「Amazon Mechanical Turk」(AMT)というサービスを提供しているのですが、今では大手ハイテク企業がこのAMTのユーザーを機械学習の支援用として活用しています。
Amazon Mechanical Turk – クラウドソーシング用のマーケットプレイス | AWS
https://aws.amazon.com/jp/mturk/
Inside Amazon's clickworker platform: How half a million people are being paid pennies to train AI - TechRepublic
http://www.techrepublic.com/article/inside-amazons-clickworker-platform-how-half-a-million-people-are-training-ai-for-pennies-per-task/
公式サイトの説明によると、AMTは「写真や動画のオブジェクトの識別」「データの重複除外」「音声録音の転写」「データの詳細のリサーチ」といった、進化するコンピューティング技術よりもまだ人間の方が効果的にこなせるタスクを、AMTに登録されている「ターカー(Turker)」と呼ばれる人々に割り振ることで迅速かつ低コストに処理するというサービスです。
そのコスト(ターカーに支払われる対価)があまりにも低すぎるということで、2014年に「私たちはアルゴリズムじゃない」というベゾス氏へのオープンレターが公開されたこともありました。

by Kevan
Google、Microsoft、Amazon、Apple、IBM、Facebookといった大手IT企業は、AMTや同種のクラウドソーシングである「CrowdFlower」、あるいは自社で同じようなクラウドワーキングプラットフォームを用意して、こうした作業に当たっているそうです。
AMTの場合、ターカーは50万人ほどいて、およそ75%がアメリカ人で、15~20%がインド人。アメリカ人はほとんどが女性ですが、インド人はほとんどが男性。その多くは1980年から1990年に生まれた人だそうです。
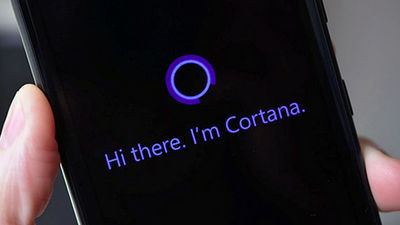
ターカーたちには前述のような、まだ人間の方が効果的に行えるタスクが割り振られるのですが、現在彼らが行っているのは「機械学習の支援」のような仕事だそうです。一例が、テスラモーターズの「自動運転」で用いられているコンピューター・ビジョン・システムやAmazonの音声認識アシスタント「Alexa」、Microsoftの音声認識パーソナルアシスタント「Cortana」です。
「完全自動運転」の力を見せつける新たなデモ映像をテスラモーターズが公開 - GIGAZINE

Amazonのハードウェア史上最大のヒット商品になったスピーカー型音声アシスタント「Amazon Echo」誕生秘話 - GIGAZINE

日本でもマイクロソフトが作ったSiriっぽい「Cortana」が利用可能に - GIGAZINE

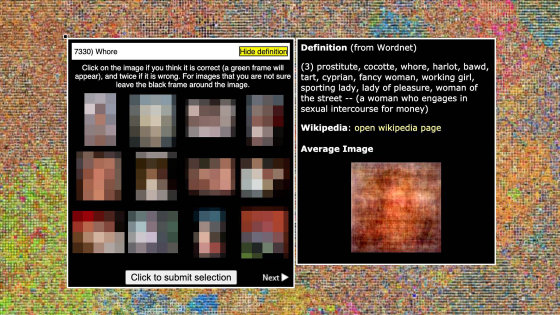
これらの技術では「カメラに写っているのは人なのか標識なのか」「音声で何を指示されているのか」といったことをコンピューターが認識しなければいけませんが、その内容は非常に複雑です。そこで「カメラに写っているものはなにか」「どういう単語が発せられたか」という内容1つ1つにタグ付けをして、AIを訓練していくことになります。このタグ付け作業を、ターカーが行っています。
扱うデータ量は膨大で、たとえばGoogleが2016年9月28日に発表した「YouTube-8M」には800万件の映像が、2016年9月30日に発表した「Open Image Dataset」には900万件の写真が含まれていて、それぞれにタグがつけられています。ImageNetではタグ付き画像1400万枚が公開されていますが、これは5万人のターカーが2年かかって10億枚の画像候補を処理した結果です。
2012年に、Googleで児童ポルノやグロテスクなコンテンツがないか監視し続けた男性の話がありましたが、ターカーたちは今まさにこの状況に置かれていて、最近では「イスラム国(イスラミックステート、IS)」を称する組織が関わったであろう、かご一杯に積み上げられた頭部の写真や、人が燃やされる映像、「流血」「切断・損壊」も「当たり前のこと」になっているとのこと。また、これも2012年の男性の話と同様に、児童ポルノについての報告も逐一行っているとのこと。
ただ、ターカーたちには依頼人が誰なのかは知らされないため、「これは児童ポルノです」と報告をしたあと、調査が行われているのか、削除されているのかといったことはわからないそうです。
こうしたタグ付けが進んでいくと、やがては人間がタグ付けをしなくてもよくなるのでは?という考えが浮かびますが、サウサンプトン大学のGopal Ramchurn氏は画像認識を例に挙げ、「我々は限界にはまだまだ到達していません。1枚1枚の写真にはそれぞれ『どの文脈でこの写真が撮られたのか』という説明が必要なので、まだ人間への依存は続きます」「たとえ5000万枚の画像にタグ付けをしても、正確に分類可能な画像はわずかしかありません」と語っています。
・関連記事
Googleで児童ポルノやグロテスクなコンテンツがないか監視し続けた男性 - GIGAZINE
自己学習する「人間のような」次世代人工知能を開発するカギとなるものは? - GIGAZINE
Googleの人工知能や機械学習をスマホのカメラやお絵かきで体験できるデモ集「A.I. Experiments」 - GIGAZINE
・関連コンテンツ