人間の発言を自由自在に書き換える音声版Photoshop「VoCo」をAdobeが発表
Adobeがアメリカ・サンディエゴで開催した開発者会議「Adobe MAX 2016」で、テキストを切り貼りしたり文字をテキスト入力することで、発言者の音声を自由自在に変えることのできるツール「VoCo」を発表しました。「画像」を自由自在に修正・変更できるPhotoshopに対して、「音声」を自由自在に修正・変更できる「音声版Photoshop」とでも言うべき仕上がりになっています。
VoCoがどのような技術なのかは以下のムービーを見れば一発で理解できます。
VoCo. Adobe MAX 2016 (Sneak Peeks) | Adobe Creative Cloud - YouTube
VoCoを発表するのはZeyu Jin(ジユ・ジン)氏。

映像左端に座るマイケルさんの音声をサンプルとして使います。
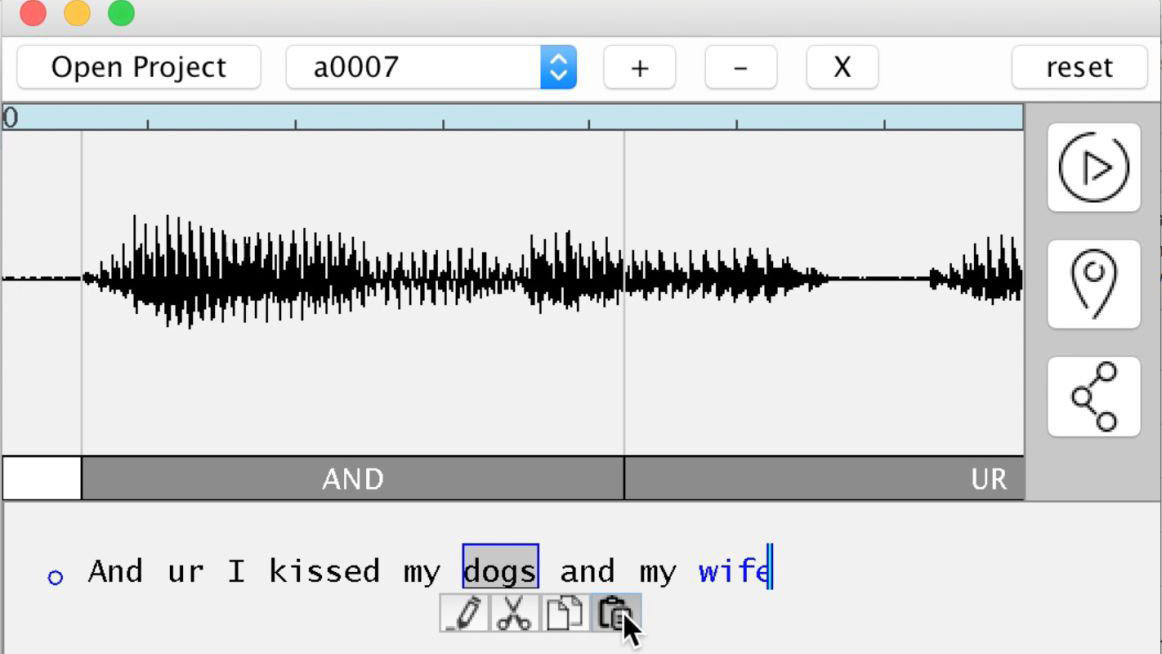
マイケルさんとの会話の中から「犬にキスをしてから、妻にキスするんだ」というジョーク部分を取り出すと、別ウィンドウにはこの発言内容が音声波形とともにテキストで表示されました。
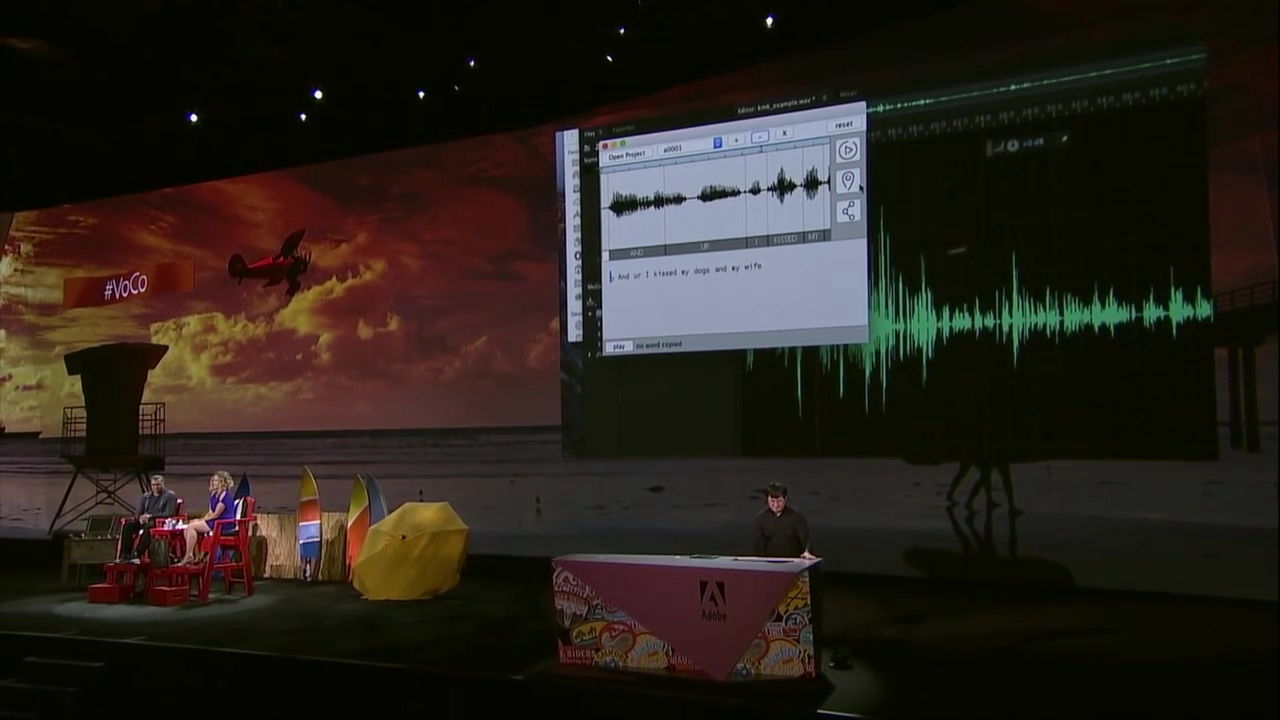
VoCoの機能は単なるスピーチtoテキストにとどまりません。「wife(妻)」というテキスト部分をコピーして「dog(犬)」という部分に貼り付けて、音声を再生すると……
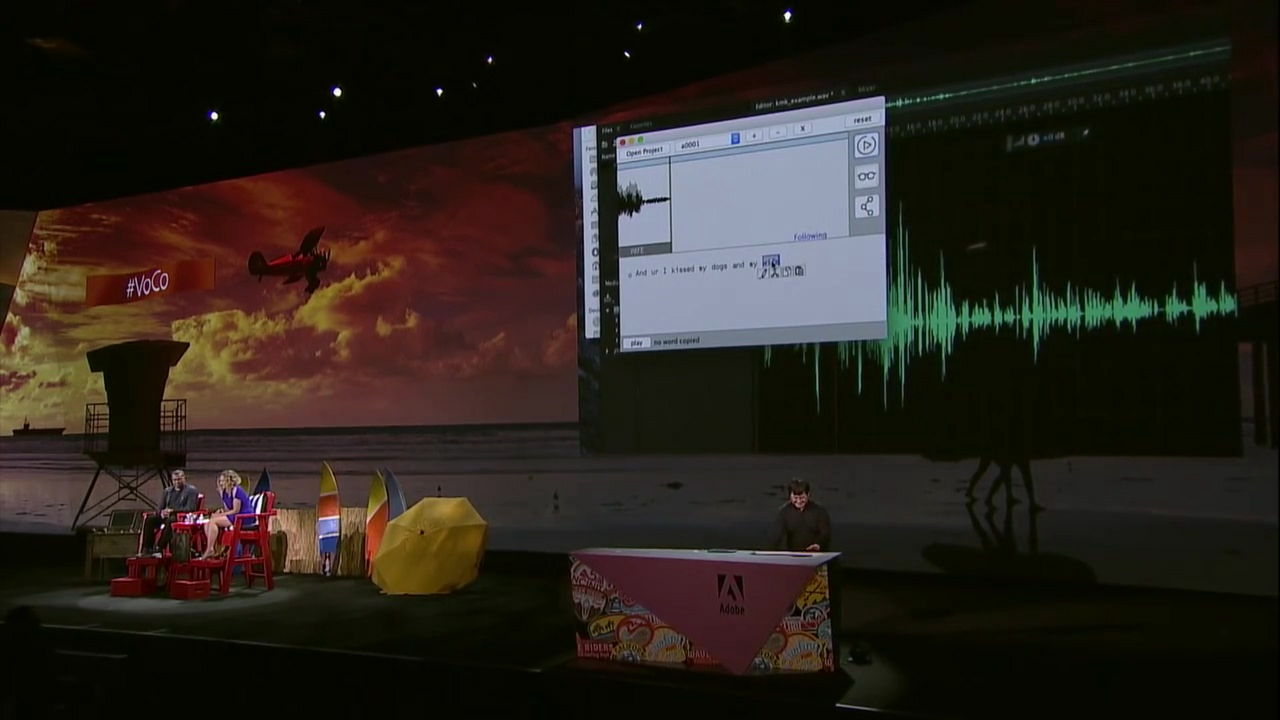
「妻にキスをしてから、妻にキスするんだ」と、「犬」の部分が「妻」に置き換わり、妻をないがしろにする発言は、一転してラブラブな発言に早変わりしました。これにはマイケルさんも苦笑い。
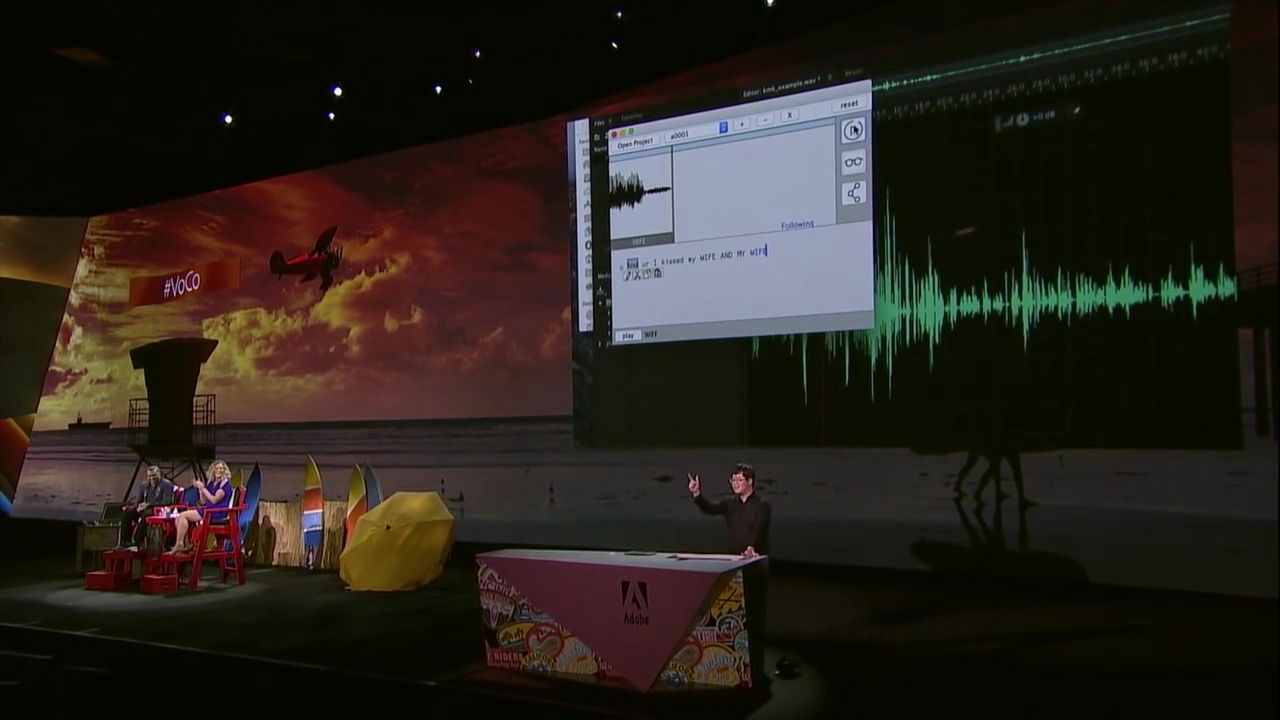
VoCoの凄まじさは単なるコピー&ペーストを超えた音声の修正が可能なところ。「wife」の部分を「Jordan(ジョーダン)」という男性の名前に変更すると……
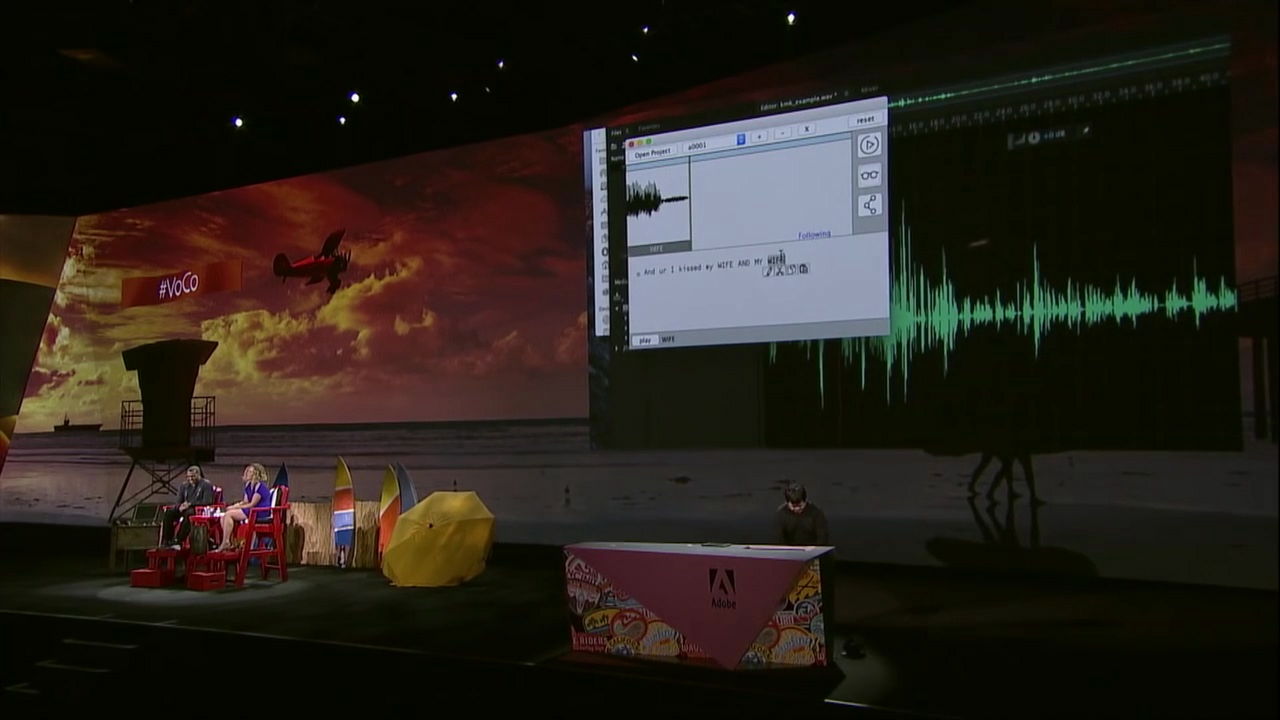
「ジョーダンにキスをしてから、犬にキスするんだ」という発言に早変わり。
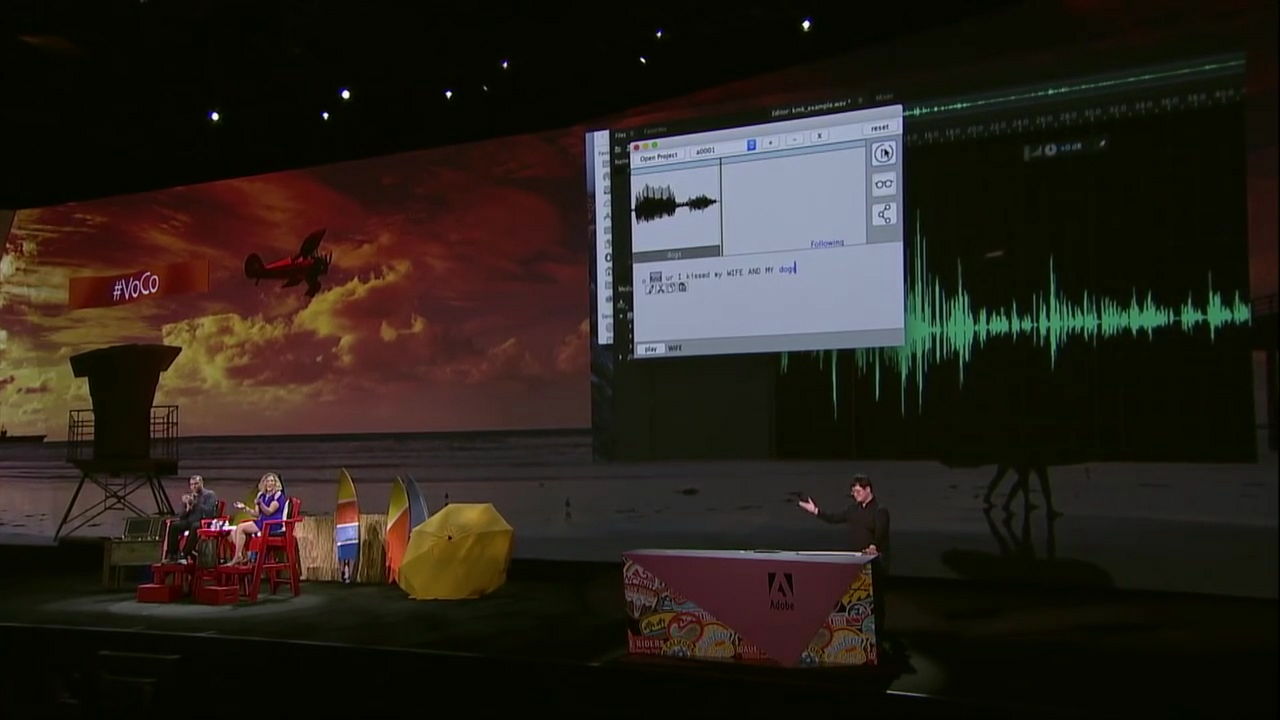
さらに「dog」の部分を「three times(3回)」という言葉に変更すると……
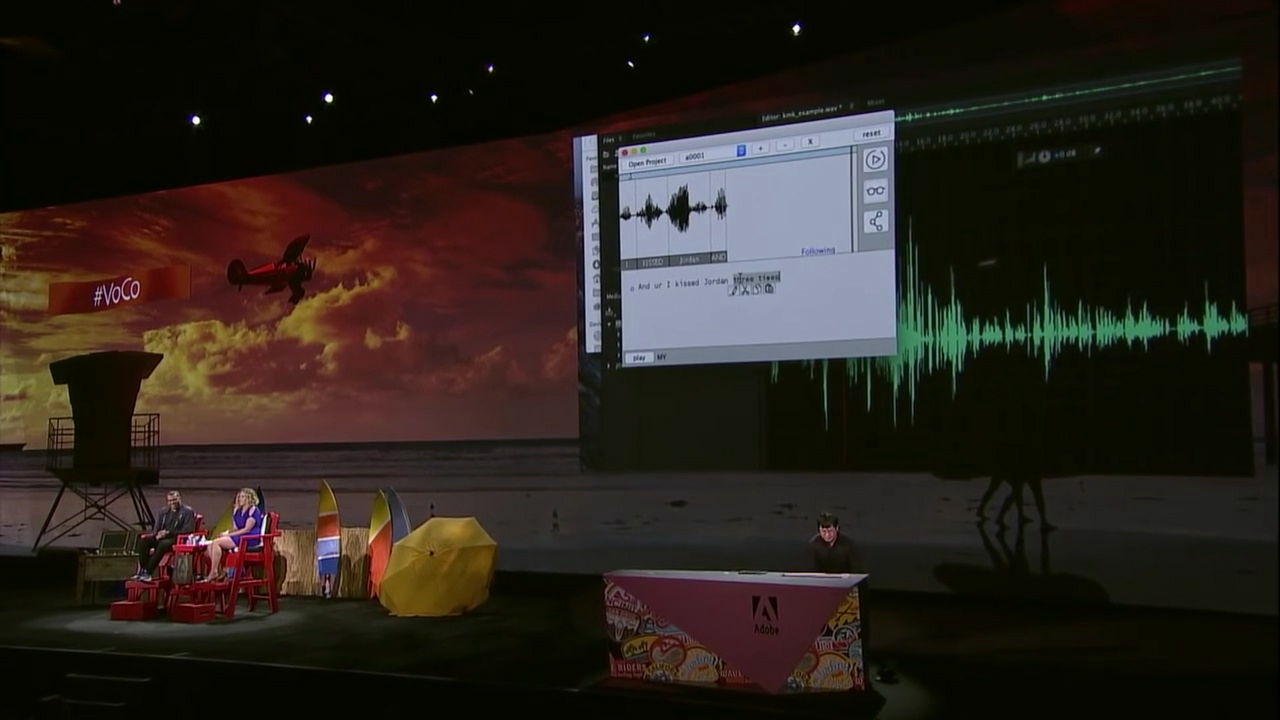
「ジョーダンに3回もキスをするんだ」という完全なねつ造発言が生まれました。
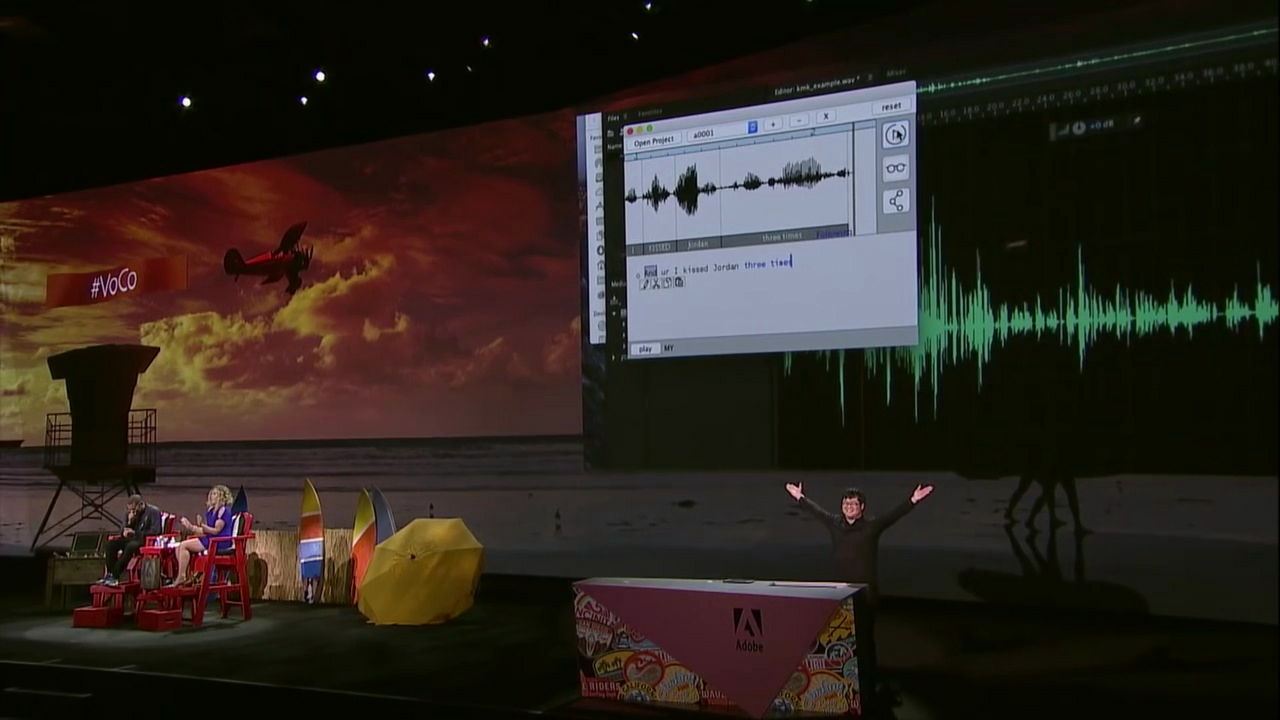
VoCoの威力を見せつけられたマイケルさんは「たった一つのフレーズから、自由に音声を作れるの?」と質問。

ジン氏は「20分程度の1つのスピーチがあれば、AudioBookのように取り扱って話者の話し方を取得することが可能で、あとはテキスト入力によって発言を修正できます」と答えています。

VoCoは、Adobeの機械学習技術「Adobe Sensei(Adobe先生)」を使ってサンプルスピーチから単語レベルを超えた話者の話し方などの特徴まで学習することができる新技術を活用しており、聞き取っていない新しい言葉をも音声として生み出すことが可能です。また、テキストから自動生成する音声データを自然な発言に聞こえるようにするアルゴリズムを使った自動修正機能も採用しています。VoCoは現時点では英語にのみ対応していますが、多言語展開は可能だとのこと。人の発言内容を自由自在に変えられる、というとんでもない未来の到来は近そうです。
・関連記事
NVIDIA&Adobeコラボで生まれた「リアルタイムで3Dの油絵を描ける」シミュレータ「Project Wetbrush」 - GIGAZINE
AdobeがUXデザイン工程を1本のソフトで完遂できる「Adobe Experience Design CC」パブリックプレビュー版を公開 - GIGAZINE
カメラに映り込む動体をリアルタイムで除去できる「Monument Mode」などAdobeの技術力をまざまざと見せつける「Adobe MAX 2015」デモ - GIGAZINE
Adobeから自由自在に新しいフォントを作り出せる技術「Project Faces」が登場 - GIGAZINE
Adobe Creative CloudがMacのデータを勝手に削除する深刻なバグが発見される - GIGAZINE
Adobeが「Flashを使うのをやめよう」ということで名前をFlash Professionalから「Adobe Animate CC」に - GIGAZINE
・関連コンテンツ