







これが5年間の技術的失敗と成功の歴史、GREEの成功を支えた技術者たちの闘いが今明かされる

「2007年からソーシャルゲームを提供してきたGREEにおける、技術的な側面での失敗と成功の実例を通じて、そのノウハウや必要な技術について解説します。合わせて、それらの経験に基づくGREEから提供していくフレームワークであるGREE Technology Stackについてもご紹介します」ということで、CEDEC2011にて講演された「GREEソーシャルゲーム5年間の技術的失敗と成功の歴史 ~GREE Technology Stackのご紹介~」はかなり濃い内容となっており、グリーの開発本部 取締役 執行役員CTO 開発本部長である藤本真樹氏と、同じくグリーの開発本部 インフラ統括部 アプリ基盤チーム リーダーの梶原大輔氏による話が次々と展開されていきました。
注目度も非常に高く、人だらけ。


今回はこの講演を発表の場にいる感覚で読んでもらえるように、当日の発表資料と合わせてまとめてみました。

藤本:
それでは、セッションを始めさせていただければと思っています。まず最初に、お忙しい中お集まりいただきましてありがとうございます。60分僕らの話をさせていただきます。「GREEソーシャルゲーム5年間の技術的失敗と成功の歴史」ということでお話をさせていただこうかな、と思っています。これは何かというと、僕らは本当にソーシャルゲームっていう名前が出てくる前、誰もそんなことを誰も言っていなかった頃から、いわゆる今で言うソーシャルゲームっていうものをずっとやってきています。で、そういうことをやっていると本当にいろんな失敗とかが多いです。当たり前ですけど、5年間やってるからそれはいろいろあります。

ちなみにそういうことは今でもあって、今日も思わず設定をミスってですね、午前中に1000通くらい携帯にメールが届くとかそういうことをやらかしたり。サービス損害がなかったからよかったんですけどね。そういうことがいろいろあったりするので、そういったこととかこういったいろんなことがありました、みたいなところを共有させていただいて、皆さんがこういったことをされる時に何らかのお役に立つようなことをお話ができればな、と。こちらにいる梶原というのがずっとGREEのサーバのバックエンドをずっと見てきたので、いろんなお話を5年間の集大成ということでしてもらおうかな、と。

あと後半はオマケみたいなものなんですけど、僕らはこういうセッションとかいろんな勉強会とかで、「こうやってます」みたいノウハウの共有はできるだけしていこうと思っていて、いろんな話をさせていただいてきました。僕らは6月決算なので、2011年7月から2012年6月期というのが始まっているんですけれども、今年の目標としてそういう無形のセッションとかだけじゃなくて、僕らのやってきたような、作ってきたようないろんなソフトのライブラリとか、あるいはドキュメントかもしれないですけれども、そういうリリース的なものをこうバシバシ公開を……ここにGREE Technology Stackと書いてありますが、まあなんか名前をつけて公開をしていって、皆さんと技術的な情報を共有していきながらですね、第一義的には「GREE Platform」ってものを盛り上げていければな、と思っています。他にこれから世界でいろんなサービスをしていくにあたって、本当に世界中の会社と競争していかなければいけないな、と。そういうところも皆さんと共有しながらやっていければなというところを、自分にプレッシャーをかける意味でも、軽くお話をできればなと思っております。ということで、60分ほどおつきあいをいただけるとうれしいなと思います。

簡単に僕の自己紹介もしておきますと、改めまして、私藤本と申します。どうぞよろしくお願いいたします。GREEの開発責任者みたいなことをしております。で、僕はずっとやっちゃいけないと思っていたんですけれども、最近はひたすらネトゲをやっています。それはいいんですけれども、そんなことをしていて、去年もこういったセッションを持たせていただいたんです。その頃はサーバ、オンラインゲームの人と一緒にしゃべったんですけど、まあそういった人たちじゃなくて、この1年で普通にクライアントだとかを作ってたような話をする人だとかも参加をするような会社になって、本当に面白くなっています。

で、今日は割とサーバ寄りの話になると思うんですけれど、楽しんでいっていただければなと思います。というところで今から梶原が30分、40分ほどお話をしますので、何かしら面白いところをつかんでいっていただけるとうれしいなと思います。というところでよろしくお願いします。
梶原:
こんにちは。梶原といいます。僕はですね、プログラミングを始めたきっかけは、父親が競馬の予想ソフトを作っていて、それに影響を受けてプログラミングを始めました。GREEに入ったのは2007年の2月で、それからずっとGREEのバックエンドを見ていて、それが主な仕事です。

早速本題に入って「GREEとソーシャルゲームの歴史」なんですけれど、最初に、当時はソーシャルゲームと呼んでいなかったんですけど、2007年5月に「釣りスタ」というサービスが出ました。そこからですね、6プロダクトくらい社内製のゲームを出して今に至る、という感じです。僕からは、この5年間のソーシャルゲームの運用中に出会った失敗だとか、その失敗に対してどのように対応していったのか、というようなことについてご紹介していきたいと思います。

この資料を作っていて5年間を振り返ったんですけれども、結構恥ずかしい障害とかいろいろあって、話すのが恥ずかしいやつもいっぱいあるんですけれども、話していきます。一応カテゴリとかつけてきたんですけれども、まず「ネットワーク」に関する失敗事例ですね。

まず最初はですね、ラックにサーバが何十台かあるんですけれど、その「ラックのスイッチのトラフィックが頭打ちしてしまった」ということがありました。これはそのスイッチのワイヤースピードみたいなものに結構限界があって、どういうことが起きるかっていうと、なんだか分からないけれど、サーバのレスポンスが結構遅くなってきて、何が悪いのかっていうのを調べてもなかなかネットワークが悪いというところまで想像力が働かなくて、ずっとアプリケーションが悪いんじゃないかとか、データベースが遅延しているんじゃないかということを調べている時に、実はMRTGみたいなグラフを見ると、トラフィックがこうビーって頭打ちになっていた、ということを発見して、そういうことも起きるんだなという失敗ですね。
対策としては、トラフィックの出やすいサーバはある程度決まっていて、それはなるべくラックを分けてサービスを乗せていこうということになりました。あとはトラフィック監視というのをちゃんと入れて、しきい値を超えたらメールを飛ばすように監視を入れました。
次にですね、「NATテーブルがあふれる」という事件です。

これはですね、GREEのウェブサーバから外部と通信をする時に、ウェブサーバってプライベートIPしかもってなくて、今は絶対NATサーバもあるんですが、まだその当時はURLとかも整備していなくって、GREEのサーバなのにプログラム内で通信しているってことも多々あって、そこらへんも整備ってものもやらなきゃいけないな、というのを最初にしました。それから内部の通信をプライベートIPに変更、と。そして外部との通信にはフォワードプロキシ(forward proxy)っていういのを利用して、それを使って通信をするようにアプリケーションを変更しました。で、それでもforward proxyのコネクションがたくさんになってなかなか機能しなくなった時には、そのサーバにグローバルIPを持たせて、そのままグローバル通信をしてもらうように設定したりしています。
次が、「DNSの問い合わせがオーバーヘッドになった」と。

これも初期の段階で、外向きのドメインというのももちろんなんですけれど、内側の、GREE内部にあるサービスのサーバもローカルなドメインを持っていてそれをわざわざ引きにいっていたんですね。それが結構DNS lookup failureっていうfailureが起きるようになってきて、名前が引けないっていうfailureが結構起きるようになってきました。これに対してはそのまま名前を使わずにIPを引けるように全て変更しました。ただIPに変えられないところもあって、例えば外部サーバもそうだし、内部でDNSラウンドロビンで回しているサーバもあったりして、それについてはIPが書けないので、それについてはローカルにDNSキャッシュを持つようにして、それで一定期間キャッシュするようにしてオーバーヘッドを解消しました。

ここまでが「ネットワーク」に関する事例ですね。次に一番多いが「MySQL」についてです。GREEはデータベースのストレージということでMySQLをメインでやったり、一番多く使っていてワナにはまったというのがたくさんあります。
このMySQLのメイン構成なんですけど、Master-Slaveの構成で、まあよくある構成です。Masterがいて、replicationするSlaveがいて、Applicationサーバからは、WriteはMasterに行きつつ、ReadについてはSELECT分はSlaveにしか投げないという構成が前提条件です。これで運用していました。

まず1個目の事例なんですが、やはり「replicationの遅延」というのがどうしても起きてしまいました。

この更新がすごい増えて、SQL threadの処理が追いつかないという、一番起きやすそうなreplication遅延ですので、これについては負荷を減らそうという単純なことなんです。忘れがちなのが1セッションというか、ひとつのページを見た処理の中で、同じレコードへデータを書き込んで、さらにそのデータを参照するようなアプリケーションを書いた時っていうのが、更新後すぐに参照するので、なかなか追いついてreplicationされてないってことが結構あって、データがないということがありました。これについては設計で防げる、と。
で、どういう対応をしたかっていうと、できるのはセッション内でキャッシュを持つっていうのが一番簡単かなと。その1セッション内で使い回す際に有効な方法です、と。何かしらその後データが変わりそうな時はやむを得ずマスターに参照を飛ばすとかもやっています。

あと、GREEの開発環境だと、こういう遅延を防ぐために意図的に1秒遅延させていて、開発時になるべく気付くような体制を取っているので、なかなか最近では見なくなりました。
次が「MySQLのMasterホストダウン」。

これも結構たまにMasterホストダウンして、どう切り替えようみたいなことがあって、ウェブ業界というかMySQL使ってるところの宿命かなと思っています。ホストダウンしてMaster切り替えする作業って結構大変で、Slaveのbinlog(バイナリログ)をチェックして、どれが一番済んでいるかなというのを探して、その済んでいるサーバをMasterとして昇格させるのを決めてあげて、そのMasterで今あるbinlogをRESETしなきゃいけなくて。よくこれはオプティマイズとかやってると、Master切り返した瞬間にオプティマイズ化して、またロックかかっちゃったとか発生するので、あとは他のSlaveで新Masterに向けてCHANGE MASTER TOして切り替えると。
あとその、MySQLサーバを管理しているファイルがあったらそのファイルをウェブサーバに配布して書き込み先を変更するってこともやるんですけれど、結構これ大変ですのでこれに対するアプローチとして、僕らはMySQLのプロキシってものを開発して、そのプロキシが勝手に切り替わるようなことをやっていました。これ名前をg2proxyっていうんですけれど、ホストダウンを検知して、SlaveのMaster切り替えをします。で、このホストダウン検知っていうのが結構シビアで、時々失敗するようなことが最初はあったんですけれども、そこを何とか切り抜けてきています。
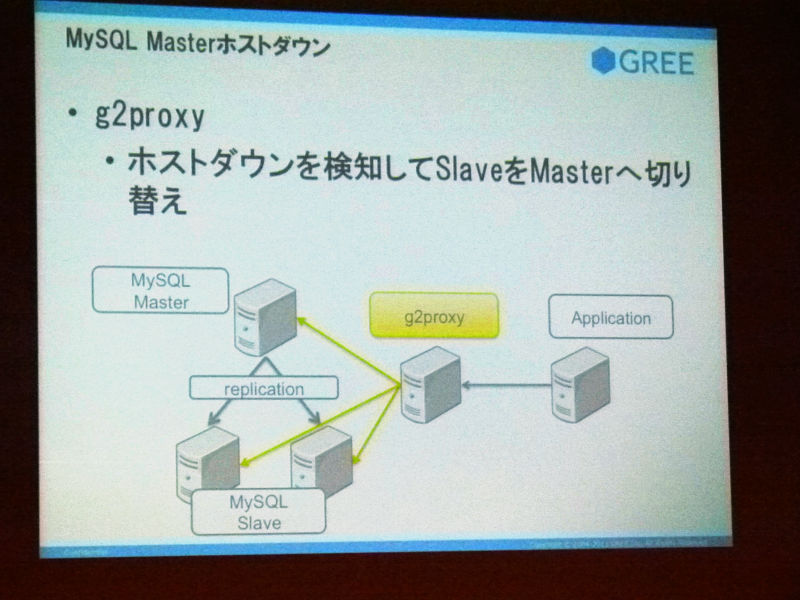
g2proxyについてですけど、Master切り替えがメインの仕事ではなくて、Slaveを複数台設定することができて、そのSlaveに対する負荷分散っていうことをg2proxyが行ってくれる、というのがひとつの機能としてある、と。

重み付けもできるので、例えば、増設した時にサーバを投入しようと思った時って、まだメモリに乗り切ってなかったりすると思うんですね。そういう時に最初は小さい重みから始めていって徐々にメモリに乗せつつ、最終的に他のサーバの重みにならすというような運用もこれで可能になってきました。コネクションのプーリングを行うというところと、さっき言ったマスター切り替えを自動的に行うといったところです。
次は、「MySQLのレコード削除」をする時って気をつけなきゃいけなくてですね、どういった事例があったかっていうと、頻繁にDELETEが発生するようなケースっていうのがゲーム中に起きて、アイテムを消費して、そのアイテムを消さなきゃいけないんで、レコード削除のDELETEを発行するっていうのが結構頻繁に起きちゃって、そのズレ、遅延が発生しやすくなるっていうのがありました。

これはルールを決めて削除フラグを追加して管理し、後で削除しようというルール・運用を今は決めています。メリットとしてはゆっくり削除することができるため、深夜に実行してゆっくりそのフラグのついたレコードを消していくというようなことができます。あとは削除済みのデータを参照できるというのがすごくメリットがあって、問い合わせがあった時に実際レコードが消えちゃってると調べることもできなくて、過去のbinlogをあさって実際に書き込んであったのか?というのを調べなきゃいけないってのが結構あったのですが、削除フラグを追加しておけば後で調べられるというのがメリットかな、と思います。
あとは、「サーバを増設する時」。

GREEでは一日に一回、深夜に専用のスタンバイサーバというのをreplicationしているサーバがあって、そこをtarで固めてるだけなんですけれども、tarで固めているやつを持ってきてそれを展開してreplicationを再開させます。大体作業するのは日中が多いので、深夜から日中までに書き込まれたbinlogっていうのはもちろん読み込めていなくて、それをいきなりStart Slaveとかやっちゃうと、Masterが勢いよくbinlogを読みに行っちゃって、disk i/oが増えてですね、メモリがあふれて違うデータが乗っちゃって、マスターが落ちるということがありました。
これは対応としては、binlogのサイズっていうものが昔は1GBだったのを200MBに変更しました。でもそれでもなかなかうまくいかなかったので、ちょっとずつbinlogを読み込むツールを作成しまして、これでなんとか一歩ずつ読んではスタックという感じで徐々に読み込んでいくようにして、サーバを構成する時には使っています。
MySQLのほぼ80%くらいのボトルネックっていうのは「書き込み」なんですよね。書き込みが激しいものについては、例えばあしあとの情報だったり友達の新着情報だったりは結構書き込みが激しくて、普通のMySQLじゃ対応できなかったりするっていうのが結構多いですね。

それへの対応としては、FlareというGREEで開発しているKey-Value-Storeのエンジンを使うというのが多いですね。

あとよくshardingと呼ばれるようなデータベース分割だとかテーブル分割だとかをやります。これについてはアクセスデータのライブラリが、shardingに対応していて、テーブル分割を100分割と言って、keyをユーザIDだとしたらそのユーザIDの下二桁を取って、0番から99番まで取りましょう、と。で、その0番から99番までのテーブルをあらかじめ作っておいて、そのユーザIDのゲストが来たらどのテーブルかっていうのをライブラリで自動計算し、そのテーブルに向けてSelectなりInsertなりを飛ばすっていうライブラリがあって、それを使うことで楽にshardingに対応することができるっていうライブラリがあります。
あとはSSDなどのハードウェアで解決って書いたんですけど、結構SSD Fusion-ioとか入ってきたのが最近で、それまでに上のふたつのことで大体対応し尽くしちゃって、実際どこで入れるかっていうのが悩ましい問題になっていて、分割するのはいいんですけれど、そこからマージとかできるのかなというと結構難しくて、実際SSDの使いどころがないというのが問題だったりします。そしてテーブル分割というとあらかじめ負荷が高そうなテーブルについては100個に分けておいて、1個のデータベースに入れておいて、その後負荷が高くなってきたらデータベースを分割しましょうみたいな、分散できるようにあらかじめ最初の方から設計しています。

ちょっと飛んでFlareの説明なんですけど、結構書き込みが激しいところっていうのは、最近このFlareを使っています。Flareは、GREEで開発中のKey-Value-Storeのミドルウェアで、特徴としてはmemcachedを使ってたんですけど、それにないようなデータの永続性だったり、クラスタを組んでデータレプリケーションしてくれたり、クラスタ内でパーティショニングをしてくれて、クラスタのリパーティションなら、クラスタが40GBと20GBずつデータを持てるとか、そんなパーティショニングとか。あとは動的に再構築ができて、FlareのバックエンドというかデータストレージというのはTokyo Cabinetを使っていて、Tokyo Cabinetをデータ追加して削除したりしていると、フラグメントってのが起きちゃうんですよね。それをデフラグするために動的再構築っていうのが必要で、その機能なんで、結構Flareの容量って大きくなっちゃうんですよ、使われるのって。それをデータをコンパクトにするのに動的再構築が必要で、結構使ってるんです。あとはノード監視とフェイルオーバーがあって、ノードが落ちた時もフェイルオーバーしてくれて、人間が作業することなくサービスを継続できるっていう特徴があったりします。あと、リクエストプロキシって書いてるのは、どこでもいいのでクラスタの1個のサーバにget setとかしていくと、実際そのサーバにはデータがなくてもそのリクエストをプロキシしてくれてデータを取ってきてくれる、と。パフォーマンスの面だと、書き込みの性能っていうのはMySQLとかも結構いいので、その面でこれが最適だと思っています。
こういうKey-Value-Storeのミドルウェアってやっぱりソーシャルゲーム業界の会社って独自で持ってると思うんです。Flareも一応オープンソースで公開しているんですけど、自分たちで作らないとかゆいところに手が届かないっていうのがあって、そういう意味合いで自前で作っていろいろ別の会社もTokyo Tyrantとかあったりするんですけれど、やっぱりかゆいとこに届かないので、自分たちで作るのかな、と。Flareはまだまだ機能拡張中で、いろんな機能が追加されています。最近だとIP的に近いところに投げるような機能が追加されていました。
あと、データストレージに「memcached」っていうのを使っています。memcachedを使っていて起きる問題としてよくあるのが「keyが分散しない問題」です。

何かというとマスターデータのように特定のkeyへの参照が集中してしまうケースです。マスターデータっていうのは、ボスの情報だとか、アイテムの情報みたいなやつをデータベースから引っ張ってきて、memcachedにつっこむ。で、ボスのデータっていうのは、例えばボスのid_1っていうのはゲームを始めた序盤の人が頻繁に参照するような情報だったり、アイテムとかもそのアイテムを持っている人は頻繁に参照するものだったりするので、これって結構偏って同じサーバにリクエストが飛んじゃうことが多々ありました。一方適しているのは、ユーザデータみたいにアイテム数が数千万、ユーザIDが数千万あるようなデータですね。keyだとユーザIDの1番から数千万あるようなkeyですね。その場合だと結構分散できるので、リクエストもそんなに偏らないし、これについては問題ないですね。
Eviction問題は置いといて、これへの対応は、あんまりかっこよくはないんですけれど、keyにランダムな値を付けようと思って付けてみました。例えばidの1だったら_1を付けるとか、10まで付けてみるとか。これでうまくいくかなと思っていたら、昔のmemcachedの最後の一文字を見ないというバグに引っかかって、全然分散されないなということもありましたね。かっこわるいけど、こういう対応はとってます。

あとはGREEはPHPを使っているので、APCというキャッシュのエクステンションがあって、普通はそのPHPのソースにリコンパイルされていないのを使うんですけれど、もうひとつのローカルのキャッシュみたいなのでkey-valueが使えてget setが使えたりするので、get setってのはAPC storeみたいなやつですが、それで保存できるので、それでそこのウェブサーバ1台分にそのデータを突っ込んでやるようになる、と。その下の方がメインで使ってますね。
で、さっき飛ばした「Eviction問題」っていうのを藤本さんに書かれたんですけれども、これは何かというと、memcachedってやっぱりそのデータのサイズってメモリのサイズなので、何十GB、10とか20GBくらいで制限があるんですね。で、あふれてくると、LRUで最近参照されていないものから消すっていう認識だったんですけれども、実際はmemcachedの中にSlabsっていうvalueに応じたメモリの空間があって、そのSlabsの中でエラービューが発生してたんですね。なので、そのメモリがいっぱいの状態でkeyをsetしにいって、そのkeyのvalueがまだ割り当てられていないSlabだと、ちょっとしかSlabが割り当てられなくて、少ないSlabを使っていて、さらにそのvalueにマッチするようなsetが来ると、少ないのでそのさっき入れたばかりのkeyが追い出されちゃうとか、そんなことが結構起きています。これはMemcachedのコミュニティとかで自動で調整してくれるものを作りそうだみたいなものを見たんですけど最近どうなのか把握できてなくて、これは本当に再起動するしかないというところです。あまりかっこよくないです。
次行って、「監視」なんですけれど、まず1個「アラートの監視」ですが、ログの監視だったりとかやります。これはNagiosを使ってました、ずっと。Nagiosを使っていて、そのNagiosがストレス限界が来て、じゃあNagiosを分割しようと分けたんですけれど、それでもサーバ台数の増加には追いつかないんです、GREE全体のサーバを見ているような監視のツールなので。サーバの増加に耐えられなくなるので、新らしく「Awacs」っていう監視キューあふれへの対応としてメッセージングキューをつっこんでそれを引っ張ってきて、エラーのフィルタリングを通してメールを投げるなりなんなりするっていうのを作りました。これもGREEで作ったプロダクトですね。

次に、監視はやるんですけれど、大体監視って5分ごとにやってるんですね。

で、5分ごとにやってると5分間隔で監視が動くんで、0分で監視して、5分に次監視するんですけれど、その間に障害が起きていると、5分くらい障害に気付かないってことが起きますよね。それで監視漏れが発生する、と。5分でも早くしたほうがいいので。あとはその5分ごとに監視する理由として、5分ごとに監視のリクエストが飛んでくると、監視サーバで時間がかかるってことで、スリープ5分間の間、ランダムでスリープさせるみたいにしていて、期待値なんですけれど均等に監視ができるような仕組みになっています。あとシビアなところは1分ごとにチェックできるようになっています。で、例えばreplicationの遅延チェックというのをやっていて、これはポジションが進んでいないとクリティカルが飛ぶようなやつがあって、これは1分間で飛ばしています。そういうのも必要に応じて変えているって感じです。
監視については障害が起きる度に監視項目を増やしていくっていう戦いがずっと続いています。最初はinodeの使用量も監視してませんでした。

inodeをなぜそんなにいっぱい使うのかというと、まずは全ユーザへ送るメルマガですけど、そのフラグ管理をファイルでタッチしてからユーザに行ってたんですけど、あふれるのが早くて、inodeが増えちゃって、その使用量をちゃんとチェックしていなかったんで、全然タッチもできなくて、メールも送れなかったんで、ちゃんとチェックしようと。
あとはreplicationチェックで監視もやるんですけど、自動で再スタートって言うのもやってくれています。MySQLのバグかはよく分からないんですけれど、ネットワークが途切れると、Statusはshow Slave Statusした結果OKってなってるんです。けど内容設定をしてみると、全然binlogが流れてこないということが起きていて、これはよく分からなくて、リコネクトみたいな名前付けのSlaveも設定しないので、なるべく短くリコネクトして対応しています。あとはMySQL table data sizeが増えることのないようにして週2回くらいdata sizeをチェックしましょうみたいな。そしてサーバの時間というのがずれやすいんですよね。ハードウェアクロックとシステムのクロックがずれているというのが結構多くて、ユニットの中にそれを入れちゃうとか。これ何が起きたかっていうと、クリノッペの誕生日がずれちゃうとかってなります。
次は「リソースの監視」ですね。リソースの監視っていうのはCPUの使用率だったりディスクの使用率だったりを監視するものです。これもサーバが増えて行くにつれて、当時使っていたのはCactiって呼ばれているやつで、これもクロールしてサーバを見に行くんです。最初は分割したんですけど、サーバが増えてくると全然クロールが終わらなくて、次のやつを考えなきゃ、と。

その前の歴史をたどると、最初はMRTGをやっていました。次にMRTGからMuninってやつに行ったんですけれど、Muninのエージェントが重いってことになって、エージェント恐怖症になって。次がGangliaなんですけれど、Gangliaのエージェント大丈夫なのか?みたいなのがあって。
今はGangliaを動かしていて、カスタマイズして使っています。監視項目については取れるデータは何でも取っていて、障害が起こった時に後で見て、障害が起こった時間にぴょんってはねているグラフはないか、みたいなことを見たりします。よくチェックする項目っていうのはdisk i/oだったりとか、load avarageだったりOSに起因するものと、あとはMySQLのクエリ数みたいなものも取っています。これはGangliaでなくても取れると思うんですけれど、そういうものも取ったりしています。あとはその、Flareとかも取っているので、それで急にgetが増えていないかとかも見ています。
あと「チート対策」ですね。ゲームなのでみんな本気で真剣に。チート対策にも真剣にやってくるんですよね。

戦ったのはURLの直接入力が結構多くてですね。これはアバターの画像のURLにhash値を埋め込みました。URLが長くなると嫌だから、8文字くらいでいいかなと思ってたんですけど、ユーザーも必死に自分でいじってリクエストを飛ばしてくるわけですね。これはもう8文字じゃ諦めないので、その時はたぶんSHAを40バイトくらい付けて、これでもかというくらい変更しました。あとは画像の連番っていうのが結構やられまして。アイテムの画像とか、カードの画像とかモンスターの画像とか、1.gifとか2.gifとか結構読まれやすくてですね。気がつくと攻略Wikiにモンスター全部載ってるとか、ありますね。なので、最近はちゃんとファイル名もハッシュ化するようにやっています。これは注意しましょう。
あとは「アプリケーション」ですか。アプリケーションの書き方はですね、SQLをどうやって定義して、投げていくかなんですけれど、SQLクエリを動的生成してるっていうライブラリもあって、それであとMySQLのslow logっていったときに、このクエリってどっから出てるんだっけってのが想像しながら探すと結構つらいですよね。

これへの対応っていうのは簡単で、クエリをベタで書いちゃうってのが僕らの回答ですね。
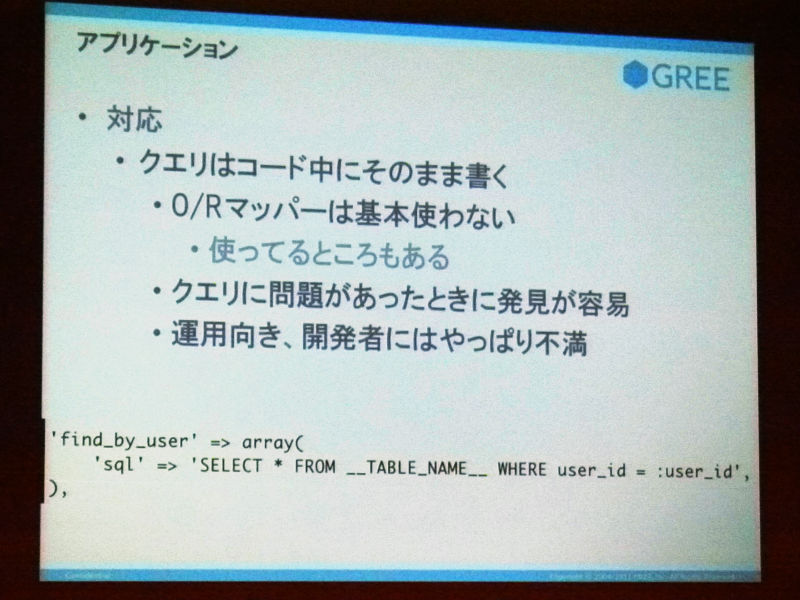
ええ、本当にそのSELECT、スタックログってなんかテーブルネームであとでこう、ベタ書きで書いていて、これやると、後でslow log出た時に、そのままここ怪しいなって言うのが一番いいかなと思ってます。O/Rマッパーは基本使っていないんですけれど、一部その、分析とかで動的にクエリ使っているようなものは使ったりしています。これは結構運用向きなので、開発者ではやっぱり不満を持っている人がいて、Rails出身者なんかは「なんでべた書きなんだよ!」みたいなことを言ったり、勝手にO/Rマッパーみたいなのを作ってこられたりするので、そこを止めるという仕事もあります。
あとは、同じクエリとかパラメタだけ違うクエリが複数発行されているとかが結構多くてですね、これへの対応は、「クエリを可視化」して見えるようにしましょうというやつですね。本当はたぶん自動的に見つければいいんですけれどそこまではいってなくて、可視化して見つけたらクエリをまとめる……「WHERE~IN句」とか、あとインサートにしてはバルクインサートを使って、効率化しましょうとか。

クエリの可視化はこんな感じでやっていて、cascadeっていうの後から出てくるんですけれど、データベースとかMySQLとかKVSのライブラリとか、そこで統合してクエリを発行する前に変数とかためておいて、最終的にページを表示する時にその変数の中身を出しちゃうみたいなやつです。

これやると結構、本当にクエリすごく投げてるやつとかは見えなくなるくらい出てきちゃうので、そういうのはこう、分かりやすいのと。あと、elapsedって書いてあるのが処理時間とかも分かって、これで時間かかって見れないかなっていうのも分かったりします。
あとソースコードがずっとGREEではひとつで管理してたっていうのが続いていて、これをやるとデプロイとかマージとかの作業が結構みんなで奪い合いになったりしてあんまりよくなかった。

それで疎結合化みたいなことをやりたくて、それでAPI化するとか、これやると異なる言語で記述することもできるようになって、いいかなと。そう思ってやっていて、やっと最近その疎結合化が進んできて、内製のゲームなのにGREEのPlatform API使ってユーザ情報取ったりとか友達と交代するようなゲームもやっと作れるようになりました。最近はAndroidとかiOSアプリとの通信部分ってやっぱりPHPを使ってないので、その部分についてはweb APIで作れるような実装ってのが用意してあって提供しています。
次にその「画像ストレージ」ですね。
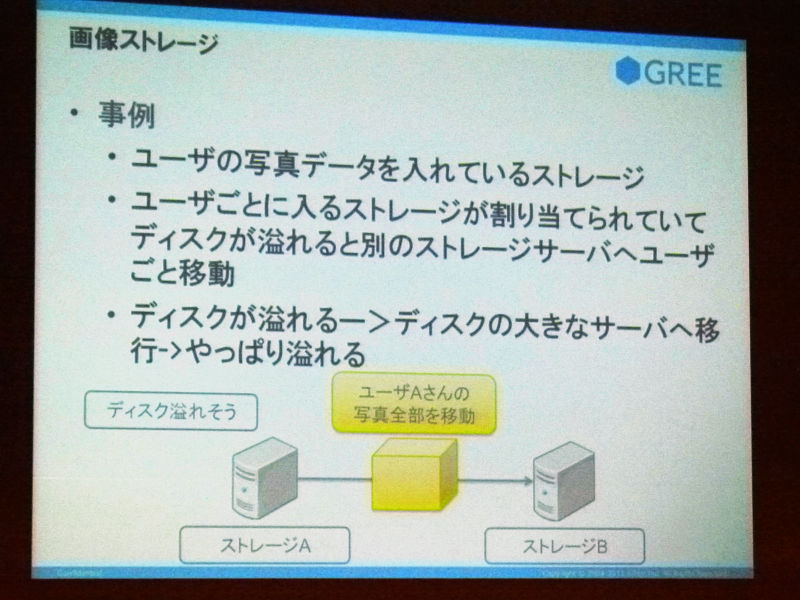
これはあの、最初はストレージAっていうところにユーザごとに写真のデータを入れていたんですけれども、ストレージAがいっぱいになってきた時にどうしようっていったら、ユーザAの写真全部を移動させなきゃいけないって事態が発生してきていて、この移動めんどくさいねっていうのがありました。
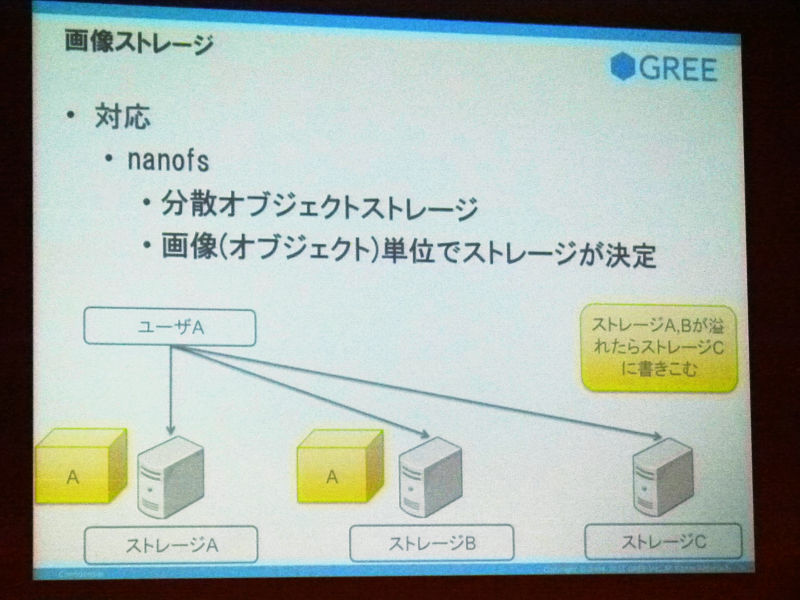
で、ディスクあふれるならディスク大きいの買っちゃおうって思って買ってみて入れたんですけれど、やっぱりあふれる日は来るので、別のアプローチを考えてみて、これもたぶん他のとかいっぱいあると思うんですけれど、画像っていうかオブジェクト単位でストレージを決定して保存するようなミドルウェアも作りました。これはnanofsって言ってまして、なぜかこれはRubyで書いてありますが、これは作者の意向です。これは、ストレージA、Bとか、ユーザAさんの写真てのはその都度空いているストレージに書き込むような形になっていると。
次に「開発環境」の話なんですけれど、やっぱりエンジニアも最近増えてきていて、最初は一台のサーバをみんなでヴァーチャルホストで共有する時代がありました。これやると、誰かがsvn upすると、その当時のsvnってまあすごい負荷あったんで、作業を中断しなきゃいけないくらいのdisk i/oが発生していたと。で、cronで朝7時とかにsvn upする人がいて、ちょうどその7時くらいに障害が多くて、そのサーバって社内からゲートウェイサーバに持っていってそのサーバをSSHに移行とかそういうのがあって。

その後、ひとり一台Linuxサーバを付与して、CDからインストールする時代になりました。これは最近まで続いてたんですけれども、これやってるとその、オフィスのサーバルームのところにサーバを置いていくんですけれど、スペースがなくなったりとか、なぜかいつもインストールCDがなくなっていて、誰か貸してくれとかそういうのがあって。
最近は仮想化環境を構築しました。これはXenクラウドプラットフォームってやつを使って構築していて、これやるとそのクラウドプラットフォームにサーバを追加すると、自動でそれを割り振って、Xenのイメージをインスタンス化して起動してくれるみたいな。これで最近はコマンドひとつで開発コマンドが作れる。で、いろんなイメージを今作っています。
そろそろ最後の方ですね。その他運用の話なんですけれど、まず1個は「障害の原因を特定しやすい環境を作りましょう」ということですね。これは最初の方はサーバが少なかったので、いろんなサービスをごちゃ混ぜでウェブサーバにつっこんでいて、で、負荷がやっぱり上がってくるんですけれど、どのサービスで負荷が高いかっていうのはやっぱり不明なんですよね。で、実は予想してたやつと分けても別のサービスで負荷が高かったりして、できればちゃんと分けたいなというのがあります。

もう1個は、memcachedとapacheってのを同居させていた時代もあって、これをやるとそのウェブサーバ分、クラスタができていっぱいのメモリストレージができて、「やった」みたいな感じなんですけれど、これも片方に引きずられて接続エラーも結構発生してしまいますから、専用のmemcachedのサーバを作っていた。これはサーバの許す限り分けることに変更しました。
最後はキャリア、まだガラケーのサーバが中心なんで、キャリアの仕様ってのに影響されやすいんですけれど、それに影響されないようにがんばるってやつです。

多いのはsmtpサーバに接続拒否されるっていうのが結構多くて、これは何とかグローバルIPがあれば受け入れてくれるので、グローバルIPいっぱい持ってクラスタ作って転送しまくるということやってます。あと、DNSの切り替えが遅いというのがあって、なぜかキャッシュのキープをするキャリアさんがいて、DNS変更したんだけれどまだリクエストが来ちゃうとか、見えないということが来て、これはまあ、Virtual IPでの運用を今でも続けています。
以上で僕からの前半部分ですね。失敗と対応みたいなことをお話しさせていただきました。後半はそれを踏まえてGREEテクノロジースタッフの説明をお願いします。

藤本:
まあ、ここから変わって、前半と言いつつあと15分しかありませんが、まあそれは5年間やってればいろんな思いがありますよね。ということで何かしら皆様のお役に立つお話があったらいいなと思っておりますけれど。結構1個1個おもしろいエピソードがあったりするんですけど、あんまり詳しく話すと怒られるんで、まあまあこれくらいで。
ええと、過去の話ばかりしていてもあれなんで、これからの未来の話なんかをして終わりたいと思っています。その話をする前にですね、僕が先ほど申し上げましたように去年ここでお話をさせていただきまして、その時は「大規模ソーシャルゲームの作り方」ってところで「60分でわかるサーバサイド技術」とか、みんな結構来てくれるんじゃないかって思って、そういう話をして、MMOのゲームだったらこうだけれど、そういうのがうちだとこんな感じでやってますとか、そういう差分をお話ししていたりとか、負荷分散はこんな感じでやってますとか、結構具体的にお話をしていて。

去年は特にCEDECとかこういう場所だと物珍しさみたいのがあって、人がいらしてくれて、すごいうれしいなと思ってるんですけれど、だいたい1年たってくるとまあ普通ですね、みたいな。というか去年しゃべった人あそこにいるんで。1年ぐらいたって何が変わったかなあと思ってみると、これはあちこちで言い尽くされていて何を今更というのはあるんですけれど、ガラケー、フィーチャーフォンからスマートフォンっていうところにデバイスのプラットフォームがシフトしているなというのはすごい感じるところです。皆さんガラケーだけ持っているっていう人は、特に開発者の方ではほとんど見なくなりました、という感じなんでそれは一番大きい。もちろん去年も普通にあったんですけどね。
そうなるとこう、プラットフォームもいっぱいあって、そもそもスマートフォンでサービス提供しようと思うと、そもそもブラウザなのかアプリなのか、問題って言うのが大いにあって、これどうしようかみたいな話がきて、じゃあアプリ作ろうかって言っても、iPhoneでつくろうとするとObjective-Cだし、AndroidだとJavaだよねみたいな。Androidでまじめにレンダリングすると皆さんご経験のとおりパフォーマンス出ないじゃないですか。結局こうcにライブラリ書き換えて使わなきゃいけないとか……。

この2つでがんばろうと思ったらWindows Phoneとか発売されてじゃあc#書こうかってなって、さすがにこれでいいかなってなったら先々週くらい、Samsungさんが独自でOS作るっていうプレスを出していて、正直勘弁願いたいなというところなんですけれど、僕らはがんばっていかなきゃいけないなというところはあります。

で、ブラウザかどうかってのも結構大きかったりして、これは延々綱引きがあるなと思っていたりします。日本だとブラウザが多いですけれど、海外だとブラウザ向けにサービス提供しているのがあんまりなかったりはするんです。こちらはセンシティブな話ですけれど、単純に課金とかする時、30%じゃないですか。高い、みたいな。ちょっと高いみたいな、とか。リリースもきつくてやだねとか言ってブラウザにみんな逃げ出す、と。微妙な綱引きが始まって……みたいなことが起こってくるんじゃないかと思っていて、僕らとしては両方考えて行かざるを得ないなと思って、振ったりはします。
まあゲームにも寄るんですけれど、ブラウザって普通に何も考えずにパワープレイでやると10から15fps位しか出ないので、そういった、fpsを要求するようなゲームはまだきついなというのがあったりしつつ。それもまあ来年くらいにはパフォーマンス上がってくるんじゃないかと思っていたりはします。本当にいろんな要素があって、これをやればOKと正直決まっていないので、なんとかしていくしかないなというのが正直なところです。
あと、本当にやってて思うんですけれど、アプリケーションってスマートフォンになると一気に複雑になりますよねっていうのがあって、ブラウザ屋ってHTML書けばいいじゃんっていう話なんですけれど、HTMLファイルをまじめに勉強しなきゃいけないし、Canvasとかやると、何しろ普通のウェブやってた人とは全然違う世界のプログラミング内容なんで。そもそもJSも覚えなきゃなんないしマシンもあればCSS3も覚えなきゃいけないのもあるし、ネイティブの方に行くと3Dのプログラミングだみたいな話もあるし、ミドルウェアとかいくつかありますけれど、そういったものも勉強していかなければならないなというところはあったりですね。

まあ今までが簡単すぎただろうっていうのもありますけれど、大体あの、普通に同じものを作るにしてもフィーチャーフォンに比べてスマートフォンで何かやろうとすると3倍くらいコストかかるねというのは見てかなきゃいけないかなというのが最近は話されているのかなと思っています。そういうことやるとミドルウェアとか作ったりしていかなけりゃならないな、と。さっきの方法で言えばUnityとかその他いろいろあったりするんですけれど、ミドルウェア使えば楽勝かというとそういうわけでもなくて、それを使うためのブリッジみたいなものとか、そのミドルウェア上でのライブラリみたいなものとかいっぱい使っていかなけりゃいけないのかなとか。

あとUIライブラリだとオープンソースのものがあったり、Facebookさんの出しているライブラリとかも自分たちで書き溜めていかなければいけないと。そういうのをしていかないとコストとかどんどん上がっちゃうんで、っていうことをみんなでやってる時期かなと思っていたりはします。で、あとネットワークのところも普通にやってかなきゃ、これは今まであったMMOのマーケットがあって普通のネットに近いものだと思うんですが、普通にsocket ioみたいなことすると、通信環境不安定なのが前提じゃないですか。ってなるといろいろシビアだなっていうのがあったりとか、どうやってデータを同期しようとか。これは本当ゲームでよくやってるのがゲームのいろんなアクションの1個1個ををイベントとしてローカルにためておいてどっかのタイミングでサーバに入れて、サーバでロジック型にイベントの順番が正しいかと検証しながらサーバ側のマスターデータをアップデートしていくというようなことも、みんな同じことをしているな、と。

となってくると本当にチート対策がシビアですよね。httpsでやってるから大体中身のぞかれないだろと思ってたりするんですけれど、Androidとかでルートドライブ見るとローカルにhttpsのプロキシを立てて、その先はhttpみたいなことをされたりするんで、なかなかhttpsだからデータのぞかれないとかではないというのは、この間サイバーエージェントさんとの勉強会で勉強しました。これはこれで大変だな、みたいな。

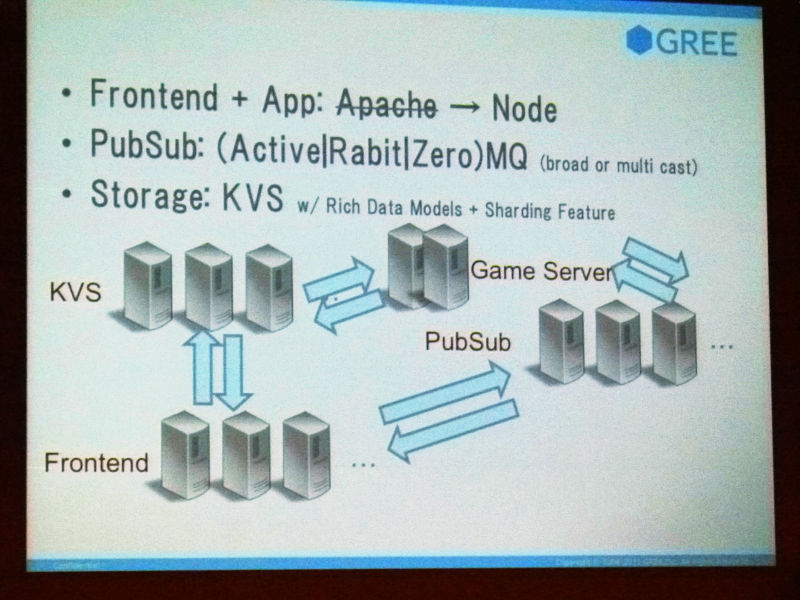
サーバは同じでいいかなと考えると、やっぱりそうではなくて、うちも今までやってきたりもしてるんですけど、普通にsocket張ってなんかしようなんてなると、普通に今までのサービスやってたようなウェブサーバでいいんだっけ?みたいなことになる。するとなかなかそうもいくまいということになってきたりする、と。なのでこの辺もシフトしていかなければならないと。なにしろ開通が大変になるなとというのは思っているところです。まあ、今の話皆さんも実感されているところかなって。
もう1個スマートフォンに行きましたってなると、ガラケーでサービスしていると必然日本だけにしかできないんですけれど、スマートフォンでやると逆に日本だけにやる理由がないねって話、そのまま海外でもやればいいじゃんみたいな話とか。
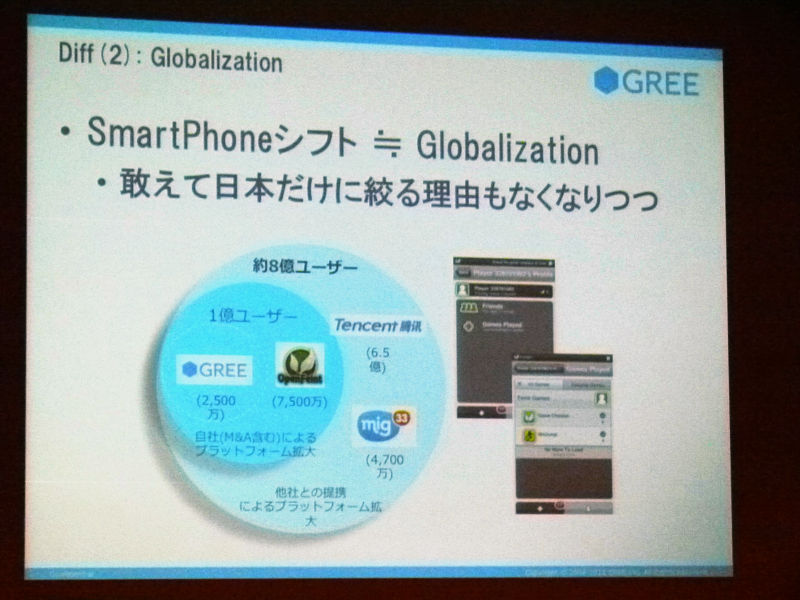
PCとかまあそうだったんですけど、とりあえずメッセージカタログだけ英語にするだけですむなら出しちゃった方がいいよね、とか。マーケットは広い方がいいので、という話になってくるんですけれど、これは内側からも外側からも壁がなくなってくるんで、世界中のデベロッパーさんと競争していかなきゃならないということになって、まあ僕らも日々大変だなあとなりつつ、がんばると。GREEも結構この辺は大変な思いしながらがんばっているところであるというのを肌で感じています。

あともう1個は手前みそであれなんですけれど、GREE Platform。去年の9月ではまだ出て2、3ヶ月だったんで、これどうなるのみたいな感じだったんですけれど、1年やってみるとおかげさまでアプリケーションは1000とかになってきて、パートナーさんも数百とかと一緒にやることができて本当にありがたいなと思っています。それだけ僕らも皆さんに一緒にやっているメリットっていうのを提供していけるようがんばっていかなければならないなと。

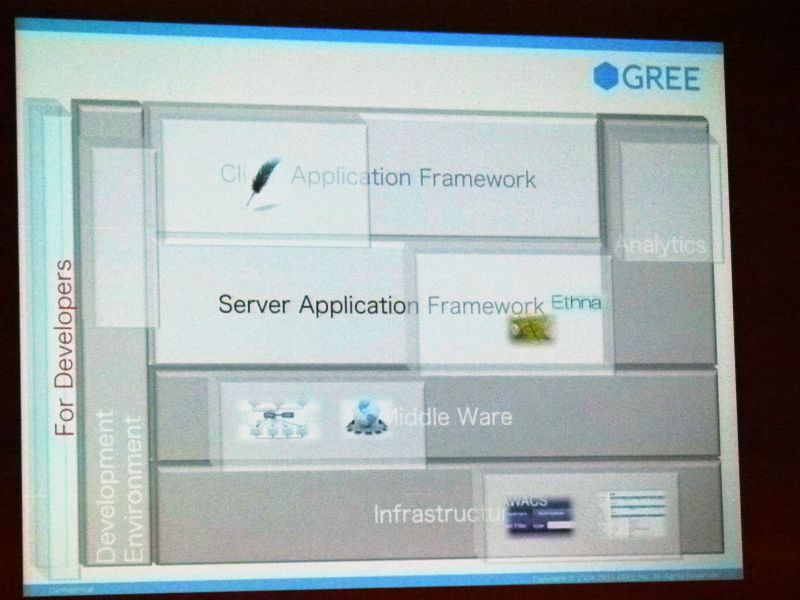
というようなところをぐるぐる考えると冒頭でお話をさせていただきましたとおり、こうやってノウハウを共有するってだけじゃなくて、僕らの技術基盤みたいなものを全部やると、僕らの会社つぶれちゃうかもしれないんですけれど、できるところとかを一緒に出していって、ものによってはオープンソースにしたりして、皆さんと、都合のいいことを言えば、一緒に開発していくことで開発のスピードとかを上げていきたいです。
本当に海外とか動きの早いところは動き早かったりしますし、コストが低いところはかなり低かったりするので、そういうところと僕らがなんとかやっていこうとすると、そういったことも本当にまじめにやっていかないと、そのうち日本全体だめになるんじゃつまんないんで、その辺はやっていきたいと思いますし、逆に社員でこういうことを考え始めると、自分の作ったコードとかがソフトウェアのライブラリとかフレームワークとかが、社員だけじゃなくてパートナー様の厳しい目にさらされたりとか、あるいはこれは日本だけでやる話じゃないと思うので、デベロッパーにああだこうだ言われるのは面白いかなと思っていて、そういう環境を作れると面白いかなと思っています。
何でそんなことを思い始めたかというと、別の考えとして、こうやって5年6年やってくると、先ほどの梶原の話でもありましたけど、いろんなの作るんですよね、みんな。例えばですけど、さっきDNSの話とかありましたけれど、なにもDNSサーバを動かす人がいて、まあこれオープンソースになっているんでよろしければご覧くださいみたいな話とか。Bindより7倍から9倍くらい速いと本人が自慢していました、みたいな。

こういうサーバーのコンソールみたいなものを作ったりとか。

まあ後、先ほど言ったkey-value-storeのものとか。


この辺にとどまらず、クライアントでゲーム作ってるとこういった話とか、ゲーム用のツール、あとはFlashとかです。ガラケーから来るとFlash liteがすごく多いですけど、iOSとかでは再生できない問題があるので。



あと、先ほどあったようにライブラリみたいなのとか、これはデータアクセスのライブラリとか。

よくある話なんですけど、ただ実際やってみるといろんなものが必要になってくるので、僕らとしては便利に使えているものとかがあるので、こういうものありますとか、普通のウェブアプリケーションのフレームワークとかもあるんです。

あとはウェブアプリケーションの方でも、結局どういう設計が最適かとか結構悩ましくて、最近思っているのが特に規模が大きくなってくると、僕らも、ご存じの方はご存じのようにGREEは割とPHPを書くことが多いんですけれど、それだけじゃなくてどっか1カ所はRubyで書かれていて動く、みたいなこともできるようにしなきゃな、みたいなことを考えると、ある程度疎結合のアーキテクチャみたいなのも必要になってきます。最近のサーバのパフォーマンスだと、そういうのも許されるかなと思っていたりしているんで、まあそういったものとか。

今日は時間ないんで飛ばしますけど、まずはいろんなものを作っていったりするというようなことがあって、別にただ皆さんもコンソールでいろんなものを作ってくると、スマートフォンでゲーム作るとむしろ楽じゃないか?みたいなところがあるかなというのもあって、別に全部が全部これ使った方がいいとか、これが最高だとか、ていうのじゃなくって、好きなもの使って公開していっていただければいいなと思っています。

ということでとりあえず1個目ということで先ほどあったFlash liteなんですけれど、こちらHTML5で再生するようなJSのライブラリみたいなのがとりあえず1個目に出していて、こういうのを続けていければいいなと思っております。

今日すみません、時間ないんでえらい早口なんで恐縮なんですが。
で、そういった感じでGREEのテクノロジーみたいなところを皆さんと共有していってですね、いろんなものを作っていけるとPlatformとして、発展していけるといいなと企んでいます、というお話でした。
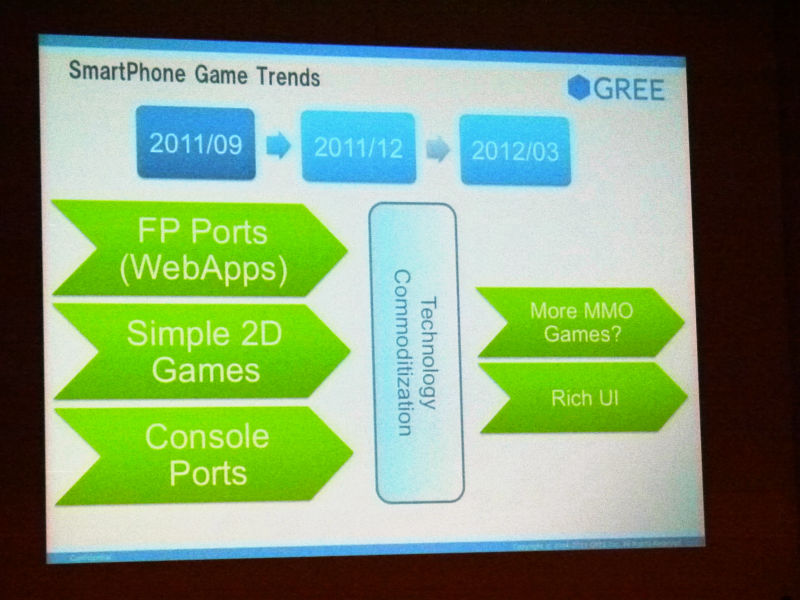
ついでに、なんですけれど、今やっているスマートフォンとかで、今年はスマートフォンということでお話するんですけど、やってることってとりあえず今までPCとかあるいはガラケーのサービスでやってきたことっていうのをスマートフォンでいろいろやってみようっていうのとか、あとは割とシンプルな2Dのゲームみたいのがメインになるっていうところとか、あとはコンソールゲームにあったのがこう移植されているとか、シュタインズ・ゲートは超(ここは小声で聞こえない)なんですとか、そういう話とかがあって、こういうのってやっぱり今トレンドだし多いなと思っていて、逆に言うとそういうところのテクノロジーっていうのはこの3か月、半年くらいですごいコモディティ化になってくるし、大体のノウハウとかもそろってくるし、ライブラリとかもいろんなものが出てくるのかなと思うと、作るコストっていうのはどんどん下がってくるし、下げていくように僕らもみんなでがんばっていかなきゃならないな、と思っています。
言った後に、じゃあどういうことしていこうかと、まあ別にそこで技術基盤だけがゲームの構成要素じゃないのは皆さんよく分かっていらっしゃるとおりなので、それはそれでいろんなことをやっていくっていうのは続いていくと思うんです。

技術面っていうところでチャレンジってまあ、今年、来年とか来年後半とかどんなことをしていくと面白いかなと思っているのはふたつあって、1個はMMO、いろんなゲームとかあるんですけど、やっぱりワールド別れるじゃないですか、いかんせん、みたいな話があって。で、まあ各スマートフォンってどのみち拘束時間が短くなるし、通信も不安定なんで、すごいまじめなリアルタイムを準備しても結構しんどいなってなると、そういうゆるいリアルタイム性をなんとか利用して、その代わり1万人とかじゃなくて、10万人とか100万人とかで1ワールドを作れるぐらいの、マッシヴなオンラインゲームが作れると面白いな、と。

本当に0.1fpsくらいならできるんじゃないかな?みたいなことを思っていたり、そういうところがチャレンジです。あともう1個、すごいハイエンドなテクノロジーを利用したゲームみたいなのは、デバイスの進化とともに結構出てくるのかな?と思っていまして、こういったところにもつっこんでいって、いろんなものを作っていけるといいかなと思っています。
そういったところも、テクノロジーっていうのも差別化要素になってきて、この辺は技術屋さんとしては追っていけるんじゃないかな、と思っています。サーバサイド、クライアントサイド、他でこんなことができると面白いなと思っています。

こんな話をつらつらしようかなと思っていたんですけど、あまりにも時間が過ぎているんで、ちょっと飛ばし飛ばしでやっているんですけれども、昨日の夜つらつら考えたところだと、意外にできちゃうんじゃないかなと思ったりもしていて、こういうチャレンジをしてみたい方はぜひGREEに来て、僕と一緒にやってみませんかと宣伝をしつつ……ええと、一応最後に軽くまとめ的な話をしておきます。

前半の話っていうのは僕らがいろんな体験をしたところの、特に僕は結構一緒にやってきたので、なんかいろんなつらい思い出がよみがえって、結構大変だったなあという話なんですけれども、そういったところがお役に立てればいいなと思っております。
そういったところからこの1年、今年ぐらいからシチュエーションが一気に変わってきています。特にモバゲーでサービスやろうというとスマートフォンとか、あとは日本だけじゃなくて世界でなんかやってかなきゃね、みたいなところをやってかないと結構未来はないみたいな感じになってきてるんで、そういったところで僕らもいろんなもの作っていきたいなと思っていますし、そういったものをできるだけ皆さんと共有しながら日本、日本ってこだわる必要もないのですけど、この業界全体を成長に持って行けるように、皆さんと一緒にそういうことができる環境を作っていきたいなと思っておりますので、よろしくお願いいたします。
ってところでちょうど1時間位なんですけれどもおつきあいをいただきまして本当にありがとうございました。ということで僕らの話を終わらせていただきたいと思います。最後早口で大変失礼をいたしました。どうもありがとうございました。

GREE Engineers' Blog | グリーエンジニアブログ
http://labs.gree.jp/blog/
・関連記事
これがWikipediaの裏側、知られざる大規模システムの実態「Wikipedia / MediaWiki におけるシステム運用」 - GIGAZINE
TwitterやFacebookで使われている「Apache Hadoop」のメリットや歴史を作者自らが語る - GIGAZINE
GoogleのChromebookが実現するいつでもどこでもアクセスできる近未来像「Nothing but the web ~100% webの世界へ~」 - GIGAZINE
Amazonがクラウドに関する「都市伝説」に反論、「AWSの真実」とは? - GIGAZINE
・関連コンテンツ







