これがWikipediaの裏側、知られざる大規模システムの実態「Wikipedia / MediaWiki におけるシステム運用」

Wikipediaといえば世界で第5位の訪問者数を誇る巨大サイトですが、システム運営に携わる人間は世界でわずか6人、しかもこれはボランティア込みという恐るべき少人数で、第4位のFacebookのサーバ数が3万台を超えているのに対して、Wikipediaはわずか350台で運用している……などというような感じで、知られざる今のWikipediaの実態が「KOF2010」にて本日行われた講演「Wikipedia / MediaWiki におけるシステム運用」で明かされました。
登壇したのはWikipediaを運営するWikimedia財団のエンジニアであるRyan Lane氏で、100席ある座席は満席になり、隣の中継の部屋まで人があふれているほどの盛況っぷりで、語られる内容もなかなか参考になることが多く、今後のGIGAZINEサーバにも活かせそうな内容でした。
というわけで、「Wikipedia / MediaWiki におけるシステム運用」で語られた内容は以下から。
会場の様子

間もなく講演開始

はじまりはじまり。なお、主催者によると、日本でWikipediaのサーバ運用に関する詳細な講演が行われるのはおそらくこれが初めてではないか、とのこと。

左にいるのがRyan Lane氏です

概要。「はじめに」「技術運用について」「グローバルアーキテクチャ」「アプリケーションサーバ」「キャッシュ」「ストレージ」「ロードバランシング」「コンテンツ配信ネットワーク(CDN)」となっています。

世界の上位5サイトについて。1位のGoogleはユーザー数9億2000万、収益は230億ドル、従業員数は2万600人、サーバ数は100万台以上。2位のMicrosoftはユーザー数7億4000万、収益は580億ドル、従業員数は9万3000人、サーバ数は5万台以上。3位のYahoo!はユーザー数6億、収益は60億ドル、従業員数は1万3900人、サーバ数は3万台以上。4位のFacebookはユーザー数4億7000万、収益は3億ドル、従業員数は1200人、サーバ数は3万台以上。そして第5位のWikipediaはユーザー数3億5000万、収益は2000万ドル、従業員数は50人、サーバ数は350台となっており、ユーザー数以外は極めて低い部類だというのがわかります。

Ryan Lane:
「世界の上位5サイトを利用者数で見ていますが、上位と下のWikipediaの差がそれほどないことを表しています。ところが実際に使われているリソース、たとえば従業員の数や収益の金額を比べると、非常に少ない売り上げ、少ないリソースで運営されていることがわかります。Wikimedia Foundationはお配りした資料ではスタッフ50人と記載していますが、実際には技術スタッフが50名というわけではなく、職員などのWikimedia Foundationの総人数が50人ということで、実際にWikipediaのシステムの運用に携わっている人数は何人くらいいるかわかりますでしょうか?」

(10名、5名、3名といった3つの回答が会場から出る)
Ryan Lane:
「実際には6名となっています。この6名とは、給与をもらっている職員とボランティアにて行っている人員をあわせて6人となっています。オーストラリア、オランダ、イギリス、アメリカなど世界中に散らばっている状態ですが、現在アジアにはまだ1人もいませんので、是非ともなってくれる人を待っています」
運用。現在6人のエンジニアで管理しており、歴史的にアドホックで「炎上消火モード」、技術者は世界中に散らばっており、いつも誰かが起きている……が「オンコール」なし。コミュニティの参加者による決定に対応しているとのこと。

Ryan Lane:
「ただ、世界中に散らばっているために、何かが起きた場合でも誰かが起きているため対応がとれるようにはなっていますが、人数が少ないため、当番制などを実施しているわけではありません。また、トラブルの際に誰かが起きていて対応できたとしても専門性の不足などが発生することもあります。
Wikipediaの歴史上からいっても、この6名というのは多い方で、本来は100%ボランティアになっており、現在のように職員というのはいなかった状態もありました。職員の募集を始めたといっても、本来はボランティアの精神ということを忘れずに運営していっており、現在もボランティアにて手伝ってくれる方々を募集しています」

Ryan Lane:
「世界中にメンバーがちらばっているからといっても、IRCやメーリングリストを公開しているため、メンバー間のコミュニケーション不足などはほとんど発生していません。基本的にはできる限り情報共有を行うためメーリングリストなどを公開していますが、ベンダーとの取引など機密情報については、メーリングリストを使わずに個人のメールアドレスを使用しており、極力、大勢に情報の共有を行っています」
運用の連絡。ほとんどのコミュニケーションはIRC上で公開、Wikiを使って文書化(http://wikitech.wikimedia.org/)しており、機密情報の連絡は非公開メーリングリストとリソーストラッカーで。

Ryan Lane:
「Wikipediaについて、非常に大きな情報を扱っているため、複雑なものを使用していることもありますが、基本の部分については、一般的な技術を使って取り扱っています」
アーキテクチャはLAMP(OSであるLinux、WebサーバであるApache HTTP Server、データベースであるMySQL、スクリプト言語であるPerl、PHP、Pythonを総称した頭文字から成る造語)

ドーピングを繰り返した結果
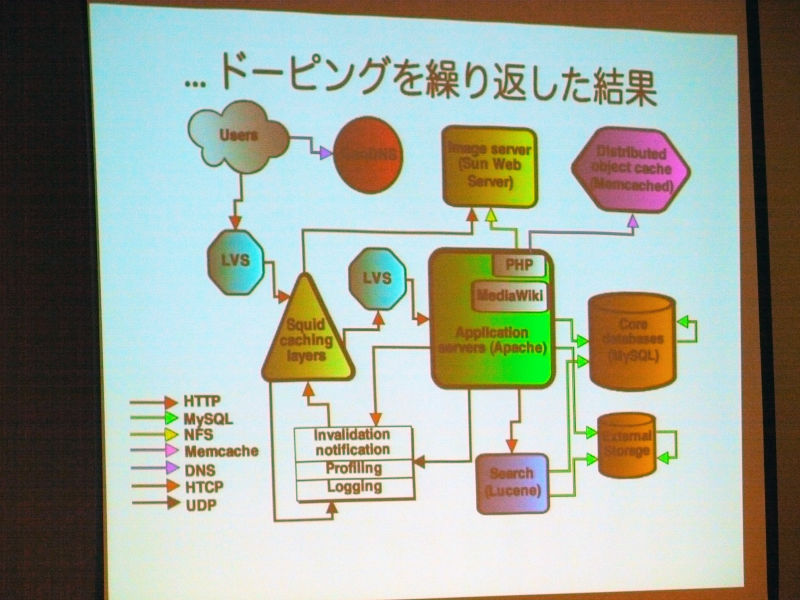
Wikiエンジンについて。全WikimediaプロジェクトがMediaWikiで稼働しており、もともとWikimedia向けに設計。非常にスケーラブル。PHPで書かれているオープンソース(GPL)。

Ryan Lane:
「まず最初にMediaWikiについて説明します。このMediaWikiについては、すべてのWikimediaサイトに使われているエンジンです。
WikipediaやWikipediaの姉妹プロジェクトであるウィクショナリー(wiktionary.org)、ウィキブックス(wikibooks.org)などについて、基本的なコアとしてはMediaWikiを使用していますが、機能性はそれぞれ違うので、これを機能拡張することで対応しています。非常に高いスケーラビリティを持っており、また、高いボーカライゼーションを備えているため、約300言語に対応しています。
ソフトウェアについては基本的にはすべてオープンソースを利用しており、ボランティアなどの開発者が約300名ほどいており、また、誰でも参加することが可能です」
MediaWiki最適化について。おかしなことをしないように、高コストな操作はキャッシュ、コードの「ホットスポット」(高負荷箇所)に注視(プロファイリングも!)、MediaWikiの機能が重すぎる場合、Wikipediaでは無効化。

Ryan Lane:
「Wikimediaをいかに最適化していくかという話になりますが、まず、「おかしなこと、バカなことを行わないように」というように、当たり前のことではあるが、一番最初に準拠しています。どのように最適化を行っているかというと、まずはキャッシュを使うということをしており、データを用意するよりも、キャッシュを用意する方が軽いという場合はキャッシュを使うようにしています。もう1つ基礎となる部分としてはプロファイリングがあり、これはデータの中で負荷が高いところを見つけてプロファイリングを行い、効率化を行っていくということをしています。このキャッシュとプロファイリングという2つの手法を使って最適化を行っています」

MediaWikiキャッシュについて。あらゆるところでキャッシュしており、分散オブジェクトであるMemcachedがほとんどのデータをキャッシュ。

Ryan Lane:
「できる限りはすべてをキャッシュしていこうという姿勢で開発しており、ユーザーのセッションから、言語別のユーザーのインターフェイスなど、すべて1から作成しなければならないよりもキャッシュできるものはキャッシュしていくということをしています。
PHPの例で説明すると、特殊な方法をしていますが、APCという手法を使ってキャッシングをしています。本来PHPの場合はインタプリタを通しての実行となりますが、インタプリタを通してバイトコードしたものをキャッシュすることで、もう一度同じリクエストがあっても、もう一度実行されるわけではないため早くなるということと、もう1つのメリットとして、メモリからキャッシュを読み出すため、さらに早くなるというメリットがAPCにはあります。
また、キャッシングとしてMemcachedを使用しています。ユーザーの方がページングを行った場合、レンダリングからすべてキャッシュを行い、メモリにためるため、次に同じリクエストがあってもキャッシュから取り出されます」
MediaWikiプロファイリングについて。http://noc.wikimedia.org/cgi-bin/report.pyにアクセスすると閲覧可能。
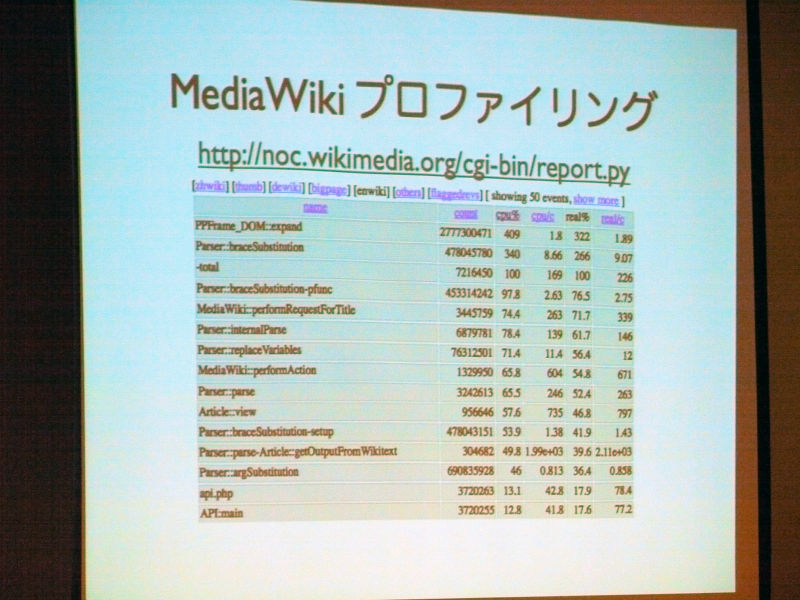
Ryan Lane:
「プロファイリングについてはMediaWikiに基本機能として実装されており、これをファイルやデータベースのUDPパケットとして記録して、どこに負荷がかかっているかを探すことができ、常時動かしています。また、常時動かすことで、新しい機能などを追加した際に、どこで問題が起きているかを早急に探し出すことが可能となっています」
MySQLについて。
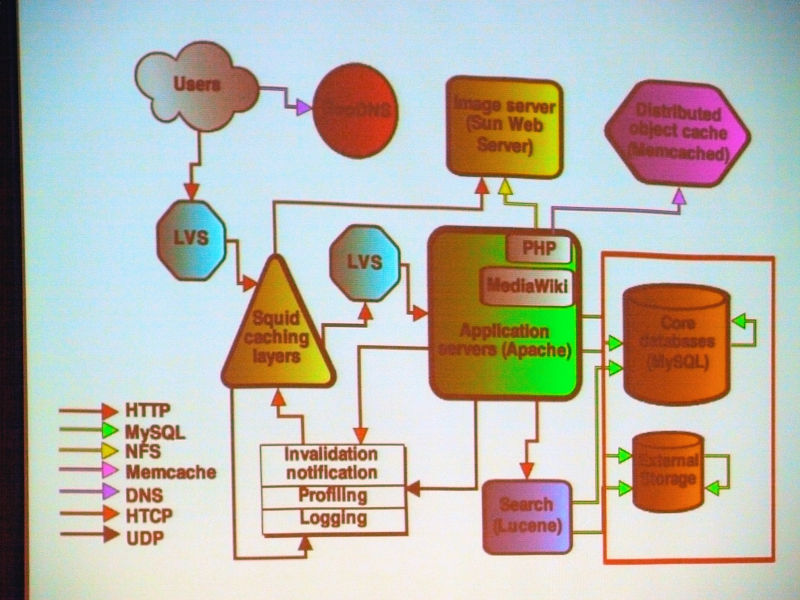
コアデータベースのMySQLはひとつのmasterにたくさんのreplicateされたslaveで構成されており、readはロードバランスされてslaveへ、writeはmasterへ。各wikiごとに個別のDBがあり、巨大で人気のあるwikiについては小さなwikiとは分離(sharding)。

Ryan Lane:
「我々のデータベースについてはMySQLを使用しており、一般的に使用しているMySQLと考えてください。
構成としては、1台のマスターに対して、複数台のスレーブを持たせることで高速化を図っており、書き込みを行う際はマスターに常に行われますが、読み出しをする場合は、複数のスレーブサーバをロードバランスして読み出すため、高速化が可能となっています。
また、Wikiごとにデータベースを分けることで、大きいWikiに対しては複数台のサーバを用意して、小さいWikiの集まりに対しては別のサーバを用意することを行っています。これを「シャーリング」と呼んでいます」
Squidについて。
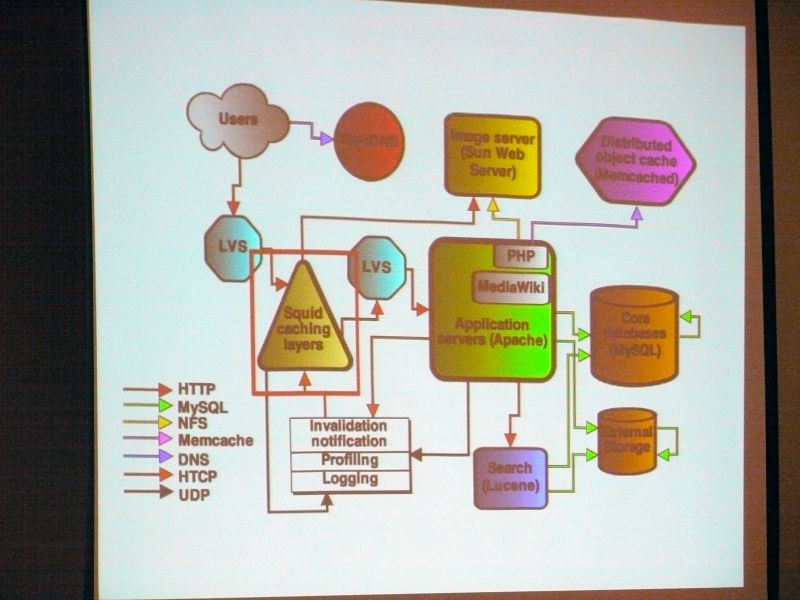
Squidキャッシングでは、リバースHTTPプロキシをキャッシュし、トラフィックのほとんどをまかなっている。3グループに分割しており、CARPを使うことでヒット率はテキスト85%、メディアファイル98%を達成。

Ryan Lane:
「キャッシングはWikipediaシステムにとってのコアシステムとなっていて、非常に少ないリソースで多いユーザーをサポートすることが実現可能となります。
Wikipediaのシステムはキャッシュに対しての依存性が高く、現在ユーザー数5000万人にも上るが実際に編集をする人は20万人程度であるため、トラフィックのほとんどは、読み出しとなっており、比較的簡単に最適化を行う事が可能です。その際にキャッシュの読み出しに使用しているのはSquidです。
キャッシュについては3つに分けられており、テキスト、メディアファイル、それと「ビッツ」と呼ばれるデータファイル、この3種類にアーキテクチャを分けています。
テキストについては、ほとんどがHTMLファイルです。メディアファイルは、静止画・動画・音声ファイルなどとなります。ビッツというのは小さなファイルのことで、たとえばJavaScriptやCSSなどのファイルになります。
これをCarpというアルゴリズムを用いてテキストファイルで85%、メディアファイルは98%のキャッシュのヒット率を実現しています」
これがCARP
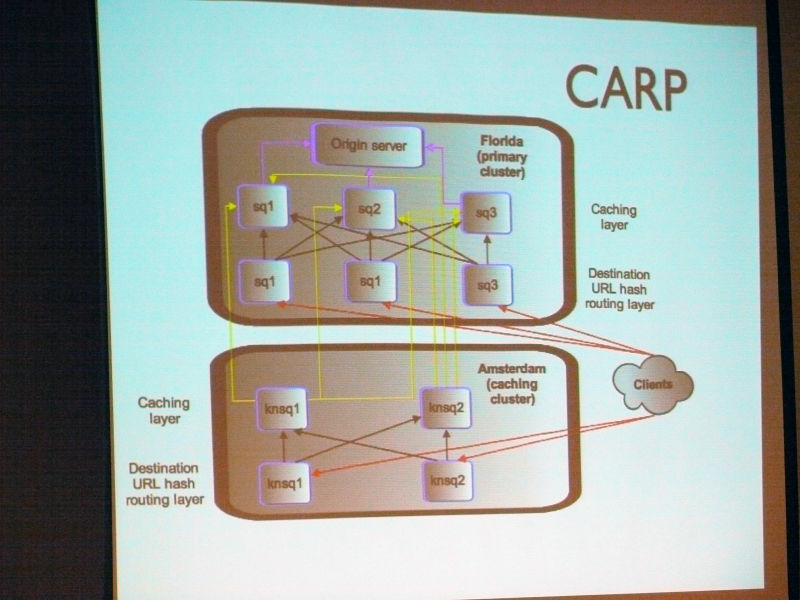
Ryan Lane:
「Carpの仕組みとして、クライアントリクエストを行うとURLに対してハッシュを作成します。そのハッシュを数値にしており、この数値の範囲であらかじめ決められたサーバが存在しており、そのハッシュ値の範囲を担当するサーバに直接アクセスする事が実現可能となります。1つのURLに対して基本的には1つのハッシュしか作成されないため、そのひも付いたサーバに割り振られることになり、必ず同じハッシュには同じサーバへ割り振りされるという事が実現されます。
また、この図はデータセンターを表したものとなっています」
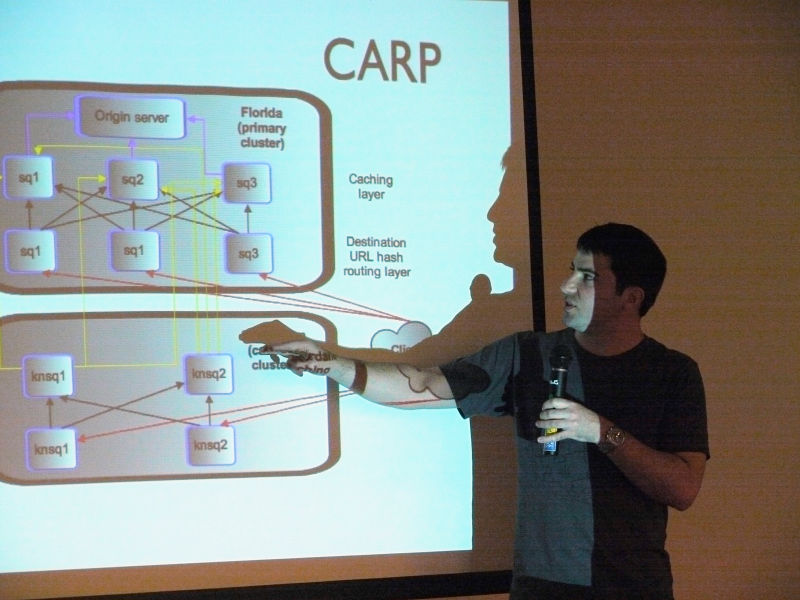
Ryan Lane:
「上のデータセンターが一次データセンターとなっており、すべてのリクエストはまず一次データセンターへアクセスされ、そこにキャッシュがなければ、最終的にはオリジンサーバにアクセスされるようになります。オリジンサーバはすべてのWikimediaサーバとなります。2つ目のデータセンターについては、オリジンサーバは存在しませんが、ここに来たリクエストはキャッシュが存在しない場合は、Squidを使って自動的にメイン(一次)データセンターへデータを取得しにいきます」
Squidキャッシュの無効化について。Wikiページは予測不可能な頻度で編集される。ユーザからは必ず最新版が見えなければいけない。一定の有効期限を使う方法ではダメ。マルチキャストUDPベースのHTCPプロトコルを使ってsquid実装によるキャッシュを無効化している。

Ryan Lane:
「Squidのキャッシュ無効化について、データを編集した場合、基本的には保存ボタンを押した後には反映されているものとユーザーは期待します。しかし、キャッシュに取り込む際によく使用される手法で一定時間が経過してからキャッシュに反映とする手法を使った場合、即時に反映されないことから使い物になりません。ですので、キャッシュの無効化の手段として有効期限を使用するという方法では使い物にならない事になります。そのため、キャッシュの有効期限を使わずに、保存されてからその都度キャッシュを無効化するといった手段を使用しています。
以前はこのキャッシュの無効化をするにあたって、有効期限を使用するといった方法が使用できなかったため、編集作業を行った後に、各Squidのキャッシュサーバに対して1つずつ個別に接続をし、対象となるキャッシュを無効化するといった作業を行っていましたが、ユーザーの数や、編集の数が増えれば増えるほど負荷が上がっていく事からこの方法は徐々になくなっていきました。
この後スタッフが考えついた方法として、UDPパケットのマルチキャストを利用して、同時にすべてのサーバにキャッシュの無効化を行えるようになり、非常に効率的になりました。
ところが、このSquidのキャッシュシステムというのは、本来リバース型のプロキシのものではなく、フォワード型のプロキシであったために、運用上で無理矢理リバース型のプロキシとして使用していったという歴史的背景があります」
Varnishキャッシングについて。現在javascriptやcssなどの静的コンテンツの配信に使われている(bits.wikimedia.org)。将来的にはSquidアーキテクチャを置き換える予定で、Squidの2倍から3倍ほど効率的。

Ryan Lane:
「徐々にですが、Varnishという新しいソリューションを使うように移行を始めています。Varnishはもともとリバースプロキシキャッシングをするために開発されたもので、Squidのプロキシよりも2~3倍ほど効率が上がっています。現在、ビッツのキャッシュについては、既にVarnishにて運用を行っています」
次はメディアストレージサーバ。
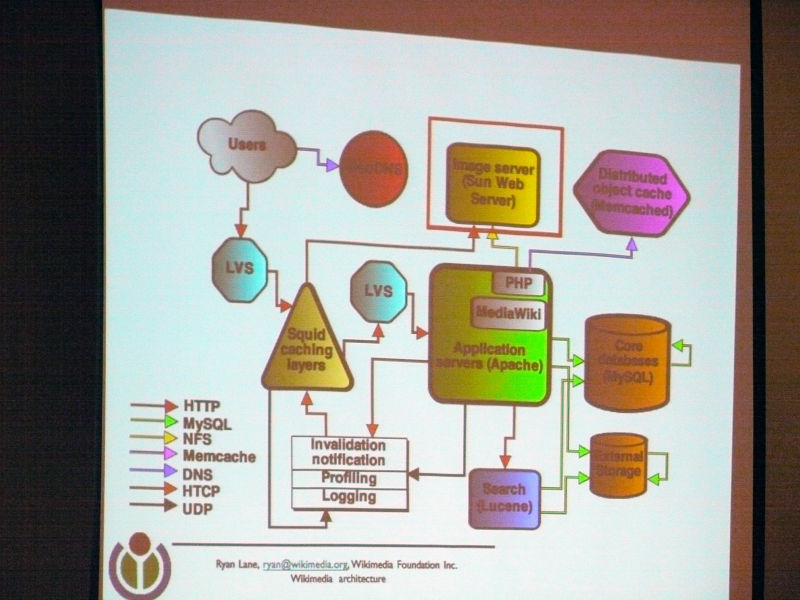
メディアストレージについて。現在のソリューションはスケーラブルではなく、多くのソリューションを検討中。オープンソースのソリューションを探すのは楽しい。

Ryan Lane:
「次にメディアストレージについて、静止画・動画・音声などを扱うサーバですが、歴史的な背景もあり、オープンソースを使っていない唯一の部分となっています。
実はこのメディアサーバの正体は、SUNのSolarisとなっています。本当は一時的に使用するつもりでいたものが、なかなか取って代わるものが存在しなかったため、今でも使用しているといった経緯となっています。
このSolarisのシステムについては、現在まったくといってもいいほどスケーラビリティが無い状態となっており、現在のキャパシティーとして、1秒間に約100回のリクエスト処理ができるのですが、常に負荷がかかる状態となっており、バックアップをとるのにも約2週間ほどかかってしまっている状態となってしまっています。
このSolarisを使ったシステムはオープンソースを使用しているわけでは無いため、自分たちで工夫して改善を行っていくことが難しいため、現在それに代わるさまざまな分散化ができるようなソリューションを探していますが、これという決め手のものが無く、検討・調査している段階となっているため、よいアイデアがある方は参加して頂きたいと思っています」

サムネイル生成について。全リクエストにstat()するのは重すぎるので、全部のファイルが存在すると仮定。サムネイルが見つからなかったらアプリケーションサーバに作成するよう依頼。
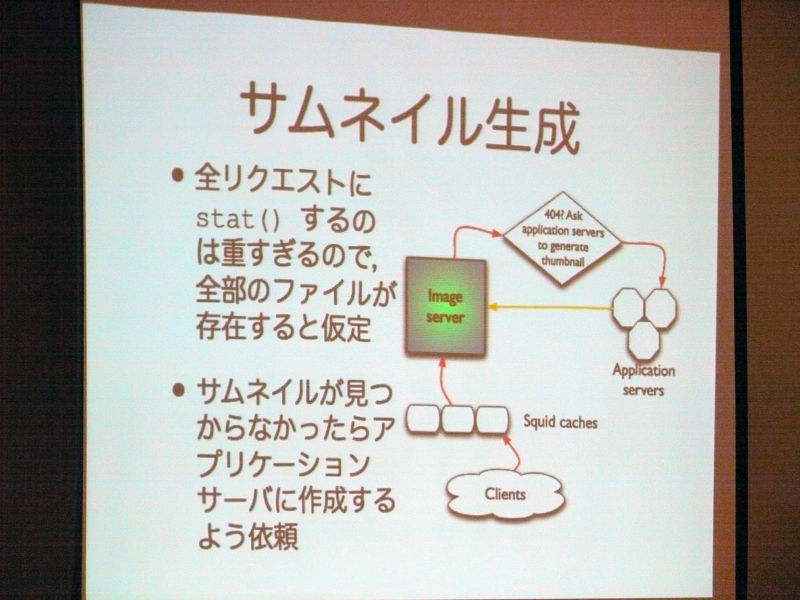
Ryan Lane:
「次にサムネイルの生成処理についてとなりますが、非常に重い処理になっており、毎回スタックを使ってサムネイルが存在するかというのを確認するだけでも時間がかかってしまう、といった背景があります。
これを回避する方法として、何があるかということを考えたところ、サムネイルが実際に存在していてもしていなくても、既にサムネイルが存在するものといった前提で扱っています。実際にキャッシュが存在すればそれを返しますが、キャッシュが存在しなかった場合、通常であると404エラーを返しますが、404エラーを返す代わりに、404エラーが発生するときにハンドラを入れ込み、実際のキャッシュが無ければサムネイルを生成して返すような形をとっています。
ですので、実際にサムネイルが存在しても、していなくても「実際にサムネイルは存在しているもの」と仮定して、キャッシュが存在すればそれを返す、キャッシュが存在しない場合は生成して返す、ということです」
次はLVS。
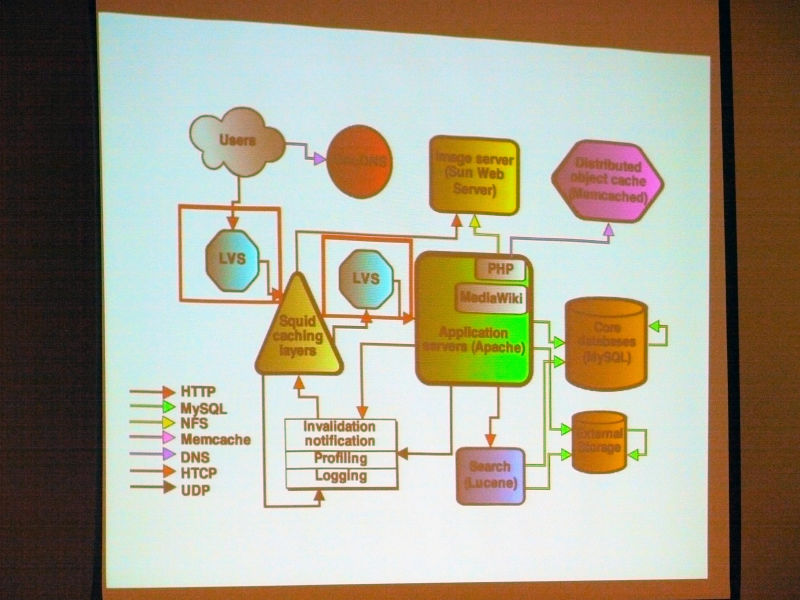
Ryan Lane:
「Wikipediaのほぼすべてのサーバはクラスタリングされていますが、クラスタリングされているということは、当然ロードバランサが必要になってきます。その中でも、アプリケーションサーバのロードバランシングとそれ以外のロードバランシングで手法が変わってきます。今回はLVSについて説明したいと思います。

ロードバランサはLVS-DR、Linux Virtual Server Direct Routing mode。すべての実サーバは同じIPアドレスを共有している。ロードバランサは上りトラフィックを実サーバに割り振る。下りトラフィックは直接届く。
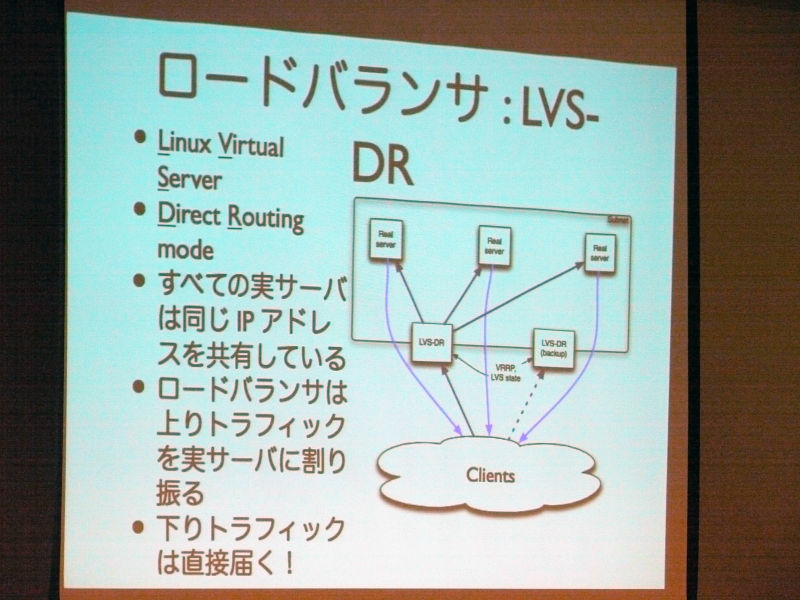
Ryan Lane:
「LVSはLinux Virtual Serverの略称ですが、これをDRモード(ダイレクトルーティング)で使用しています。DRモードは非常に効率がよく、その関係もあって、Wikimedia Foundationで持っている中でも非力なPentium 4のシングルコアといった古いサーバを用いても十分な性能を発揮してくれるので、それを使用しています。
この仕組みについて説明すると、クライアントのリクエストをディレクターが受け、それをそれぞれのサーバに振り分けるためのロードバランシングを行いますが、レイヤー3のレベルで行っているため、非常に効率がよくなっています。さらに効率がよいのが、応答を返す際にディレクターを通じて返すわけではなく、すべての分散化されたサーバが同一のIPアドレスを共有しており、ディレクターを通さずに直接クライアントへ応答を返すため非常に効率がよくなっています。入り口のところについても1Gbit程度のネットワークインターフェースでも十分であり、数多くの小さなリクエストに対して、総データ量が非常に多いものを返すことができる仕組みとなっています」
Ryan Lane:
「今までは単一のデータセンターを運用する事を前提にお話をしてきましたが、実際には世界中に複数のデータセンターが存在しており、できる限り早いスピードで供給したいということで、これを端的に言うと、ユーザーの近くにデータセンターを配置したいということになります」
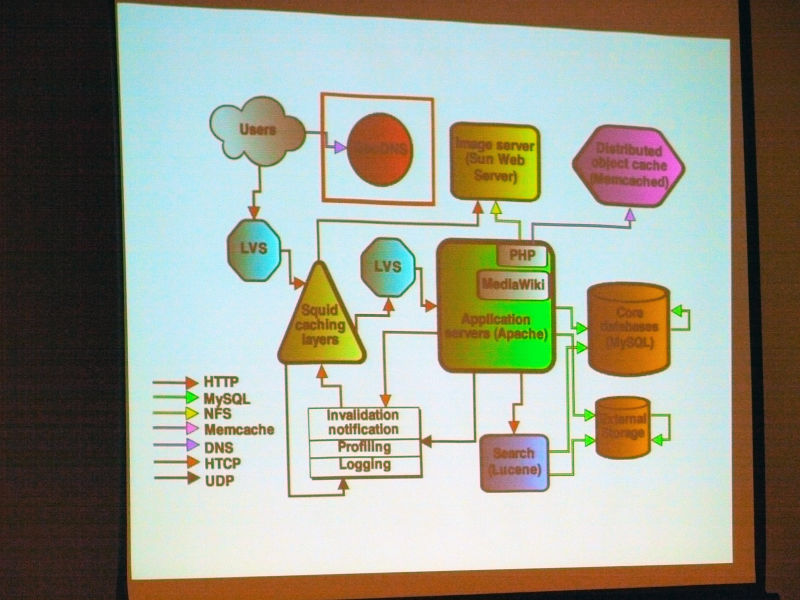
コンテンツ配信ネットワーク(CDN)について。2大陸に2クラスタあり、プライマリクラスタはフロリダ州タンパ。セカンダリはキャッシュのみのクラスタがアムステルダムに。バージニア州に新しいデータセンターをまもなく追加予定。

Ryan Lane:
「現在Wikimedia Foundationとしては2つのデータセンターを持っており、1つめ・プライマリのデータセンターはアメリカのフロリダ州タンパに存在しており、2つめ・セカンダリのデータセンターはオランダのアムステルダムにありまして、こちらはキャッシュのみのデータセンターとなっています。3つめのデータセンターとして、アメリカのバージニア州に現在新しいものを作ろうとしていまして、これができると2つのプライマリデータセンターができあがる形となります。
アムステルダムに存在するセカンダリのデータセンターには全体システムのサブセットだけがあるようになっており、DNS・LVS・Squidのキャッシングのためだけに必要なものがそこにあるといった構成になっています」
ロードバランサ部分。
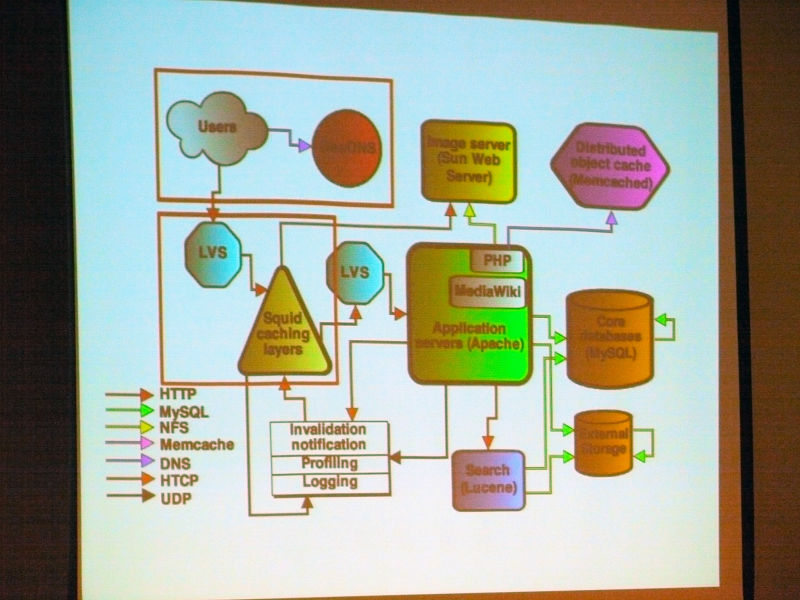
Ryan Lane:
「課題として、いかにしてユーザーを近いデータセンターへ誘導するかということになっています」
地理的ロードバランスについて。ほとんどのユーザは近くのDNSリゾルバを使う。リゾルバのIPアドレスを国別コードにマップ。国に応じて近いデータセンターのCNAMEを返す。Geobackendを有効にしたPowerDNSを使用。

Ryan Lane:
「ほとんどのユーザーは自分が使っている一番近いDNSを使っています。ユーザーが英語版のWikipediaへアクセスしようとすると、ユーザーが設定しているローカルのDNSにリクエストがされ、さらに上位のDNSにつながり、WikipediaのDNSサーバにつながって答えを返すといった一般的なDNSの流れのお話となりますが、DNSのリゾルバにリクエストがきて、WikipediaにてユーザーのIPアドレスを国別にひもづけるといったリストを持っており、それを使用してユーザーに応答を返す際に、一番近いデータセンターのCNAMEで応答を返すといった手法をとっています。
そして、ユーザーへリクエストがきたあと、ユーザーの使っているDNSリゾルバのIPアドレスをみて、場所をおおよそ特定してサーバのIPアドレスとして一番近い国のデータセンターを返すようにしているため、ヨーロッパからのリクエストに対してはヨーロッパのサーバIPアドレスを返し、同じURLでアメリカからリクエストされた場合は、使っているDNSサーバの所属する地域がアメリカのもののため、返すサーバのIPアドレスもアメリカのものを返す、といった形になります。
これを実現する方法として、PowerDNSを使い、さらにGeobackendというオプションを組み合わせています。PowerDNSについてはオープンソースですが、本来はDNSとして開発されたものではなく、世界規模のIRCを行うために開発されたものなのですが、これがDNSとしても使えるだろうということになり、IRC用に開発されたものをDNS用に応用したソリューションになります」
おわりに。オープンソース・ソフトウェアに非常に頼っている。効率を常に追求し、さらに効率的なマネジメントツールも探している。ボランティアも探している。

Ryan Lane:
「最後になりますが、我々は非常にオープンソースへの依存性が高いシステムであり、組織であります。オープンソースコミュニティーに依存性の高い組織となっているわけです。この理由としては、たとえばバグがあった場合、スケーラビリティに問題があった場合、
直接開発をしている方とコンタクトをとって解決に当たる事ができるわけですが、これを商用のソフトウェアを使用していると不可能なわけです」

Ryan Lane:
「我々は、常に少ないリソースで最大限のパフォーマンスを出すことを目指しているため、効率を高めるということは常に追求しております。同時に管理をするためのツールを改善することも行っております。もともとボランティアで始まった組織というルーツもありますので、常に協力して頂けるボランティアの方を探しているということについても変わりありません」

Ryan Lane:
「ありがとうございました」

・関連記事
GIGAZINEのLoadAverageを「27」から「2」へ下げた方法 - GIGAZINE
GIGAZINE最大の挑戦、LoadAverage「86」から「3」へ - GIGAZINE
GIGAZINE、新サーバに移転完了 - GIGAZINE
「Web 担当者 現場のノウハウ Vol.4」にGIGAZINEがインタビューされました - GIGAZINE
GIGAZINEが新サーバに移転完了しました - GIGAZINE
GIGAZINEが4月18日夕方から新サーバに移転します - GIGAZINE
GIGAZINE、ついに新サーバへ移転完了 - GIGAZINE
GIGAZINEを支えるサーバ「IBM System x3200」フォト&ムービーレビュー - GIGAZINE
想定外の壊れ方をしたDELL製サーバの復旧まで一部始終のレポート - GIGAZINE
GIGAZINEを支える2基のXeonプロセッサを搭載した8コアサーバ「HP ProLiant ML150 G5」フォトレビュー - GIGAZINE
GIGAZINEサーバで使っている無停電電源装置「APC Smart-UPS 750」のバッテリーを交換してみた - GIGAZINE
GIGAZINEサーバ電気工事の裏側を公開、本日午前9時から午後6時までの一時停電を乗り越えろ! - GIGAZINE
・関連コンテンツ