Databricks releases open large-scale language model 'DBRX', outperforming GPT-3.5 and CodeLLaMA-70B

Databricks, a company that provides data analysis tools, announced `` DBRX '', an open general-purpose large-scale language model (LLM), on March 27, 2024. It is distributed under an open license, and companies with less than 700 million monthly active users can use it commercially for free.
Introducing DBRX: A New State-of-the-Art Open LLM | Databricks

DBRX is an LLM that uses a transformer decoder and has a 'mixture-of-experts (MoE)' architecture. The total number of parameters is 132 billion, but only 36 billion parameters respond to all inputs, the remaining parameters are 'experts' and are activated as needed. By adopting the MoE architecture, it is possible to reduce the size, enable highly efficient learning and inference, and improve performance.
While Mixtral and Grok-1, which also use the MoE architecture, have 8 experts and activate 2 per input, DBRX has 16 experts and activates 4 per input. Activate. It is stated that the quality of the model has improved by increasing the number of expert combinations by 65 times.
Additionally, DBRX was trained on a total of 12 trillion tokens of data with a maximum context length of 32,000 tokens. Although it was difficult to train a MoE model with a mix of 'experts,' we developed a robust pipeline that could be trained repeatedly in an efficient manner, allowing anyone to train a DBRX-level MoE basic model from scratch. It is stated that.
The figure below shows the benchmark results for 'Language Understanding', 'Programming', and 'Mathematics', and you can see that DBRX has better results than models such as LLaMa2-70B, Mixtral, and Grok-1. Additionally, by having experts on board, we are able to ensure general-purpose performance while also ensuring performance in areas that require specialization, such as programming.
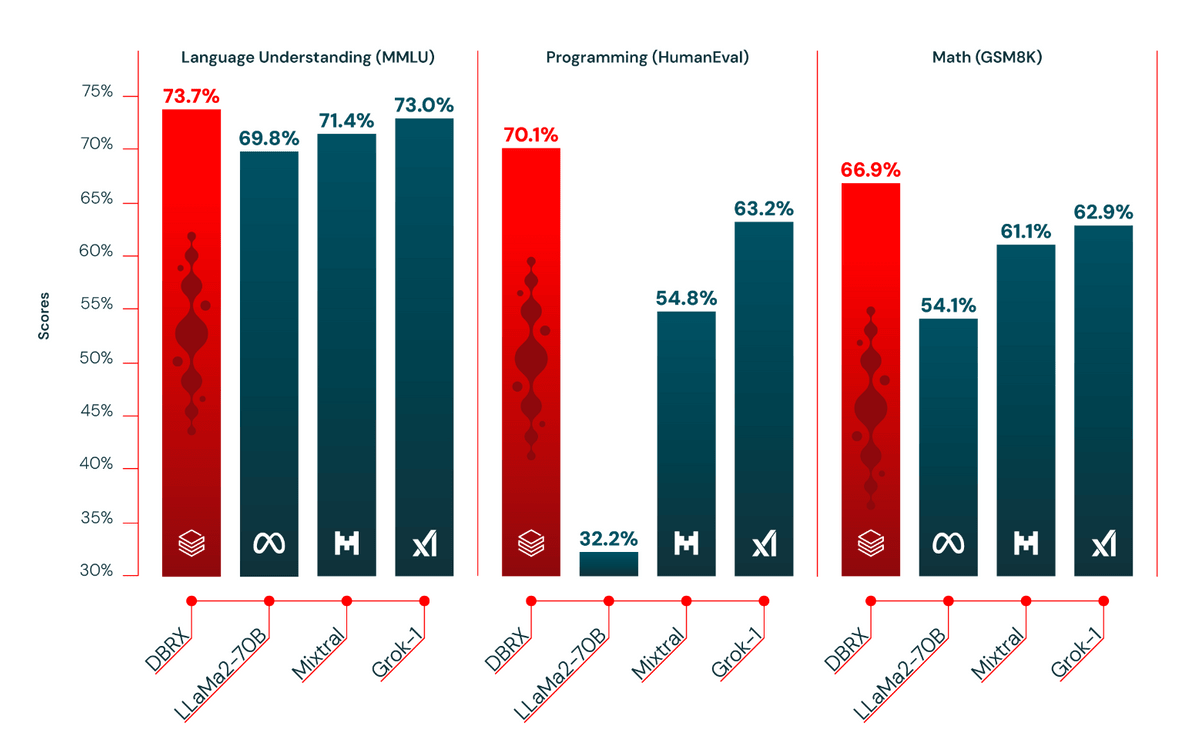
In addition, the comparison results with closed source LLMs such as 'GPT-3.5', 'GPT-4', 'Claude 3 Series', 'Gemini 1.0 Pro', 'Gemini 1.5 Pro', and 'Mistral' are shown in the figure below. At a glance, DBRX Instruct appears to be on the same level as Gemini 1.0 Pro and Mistral Medium.
Model | DBRX | GPT-3.5 | ||||||||
MT Bench ( Inflection corrected , n=5) | 8.39 ± 0.08 | — | — | 8.41 ± 0.04 | 8.54 ± 0.09 | 9.03 ± 0.06 | 8.23 ± 0.08 | — | 8.05 ± 0.12 | 8.90 ± 0.06 |
MMLU 5-shot | 73.7% | 70.0% | 86.4% | 75.2% | 79.0% | 86.8% | 71.8% | 81.9% | 75.3% | 81.2% |
HellaSwag 10-shot | 89.0% | 85.5% | 95.3% | 85.9% | 89.0% | 95.4% | 84.7% | 92.5% | 88.0% | 89.2% |
HumanEval 0-Shot | 70.1% temp=0, N=1 | 48.1% | 67.0% | 75.9% | 73.0% | 84.9% | 67.7% | 71.9% | 38.4% | 45.1% |
GSM8k CoT maj@1 | 72.8% (5-shot) | 57.1% (5-shot) | 92.0% (5-shot) | 88.9% | 92.3% | 95.0% | 86.5% (maj1@32) | 91.7% (11-shot) | 81.0% (5-shot) | |
Wino Grande 5-shot | 81.8% | 81.6% | 87.5% | — | — | — | — | — | 88.0% | 86.7% |
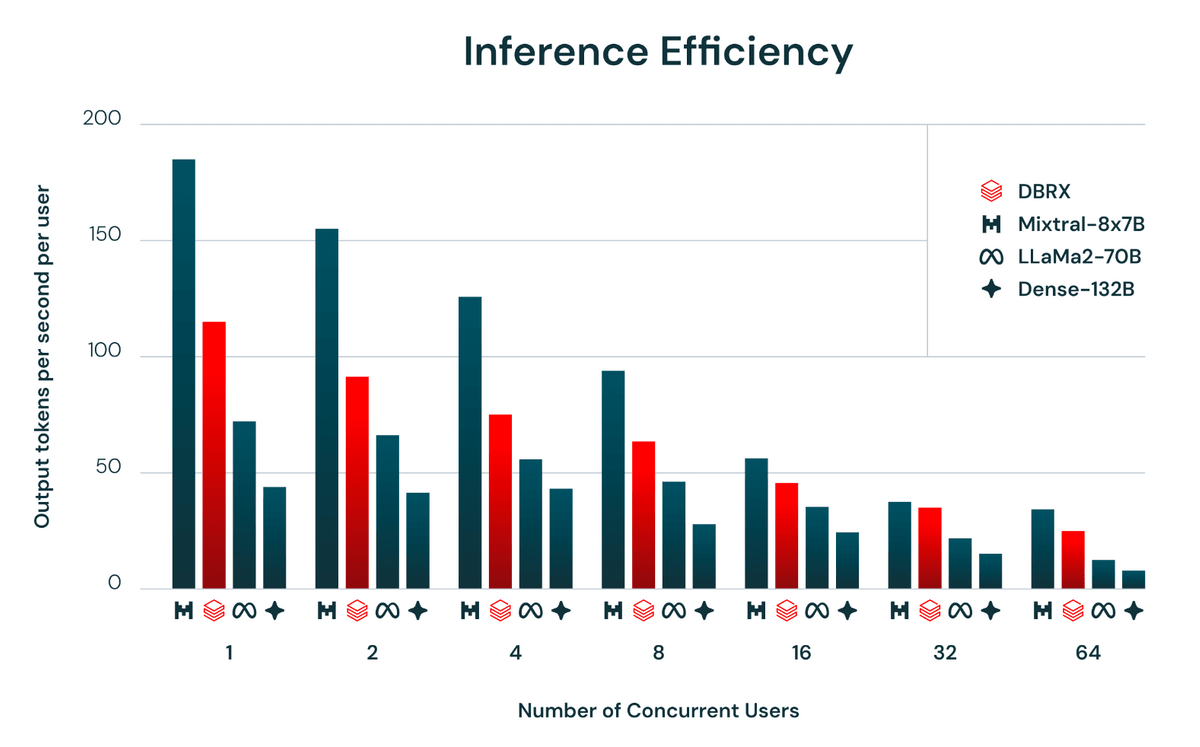
The figure below shows the number of output tokens per second per user, which indicates the efficiency of inference. The smaller model, Mixtral-8x7B, has the highest output for both user counts. On the other hand, the inference efficiency of DBRX, shown by the red line, greatly exceeded LLaMa2-70B and Dense-132B.
Both the basic model `` DBRX Base '' and the fine-tuned model `` DBRX Instruct '' are distributed under an open license on Hugging Face, and can be easily used via Databricks' Foundation Model API .
Related Posts:







in Software, Posted by log1d_ts