Google announces ``MobileDiffusion'', an approach that can generate images in 0.5 seconds using a smartphone
There are several AI models that generate images based on text, but the main models that generate high-quality images process billions of parameters and generally require a device with powerful specifications. . On January 31, 2024, Google engineers announced an approach called MobileDiffusion , demonstrating how images can be efficiently generated even on mobile devices such as smartphones.
MobileDiffusion: Rapid text-to-image generation on-device – Google Research Blog
While models such as Stable Diffusion and DALL-E are evolving, methods for generating images quickly on mobile devices are less advanced. In particular, when the number of trials (steps) such as 'sampling' that generates high-quality images by repeating noise removal increases, the specifications of the mobile device may not be able to handle the process. Previous research has focused on reducing the number of sampling steps, but even if the number of sampling steps is reduced, generation may still take time due to the complexity of the model architecture.
Therefore, Google developed 'MobileDiffusion'. Google positions this as an 'efficient latent diffusion model designed for mobile devices,' and it is specialized for mobile devices, such as generating high-quality images of 512 x 512 pixels in 0.5 seconds on Android and iOS devices. It is said that they have created an image generation model that uses the following methods.
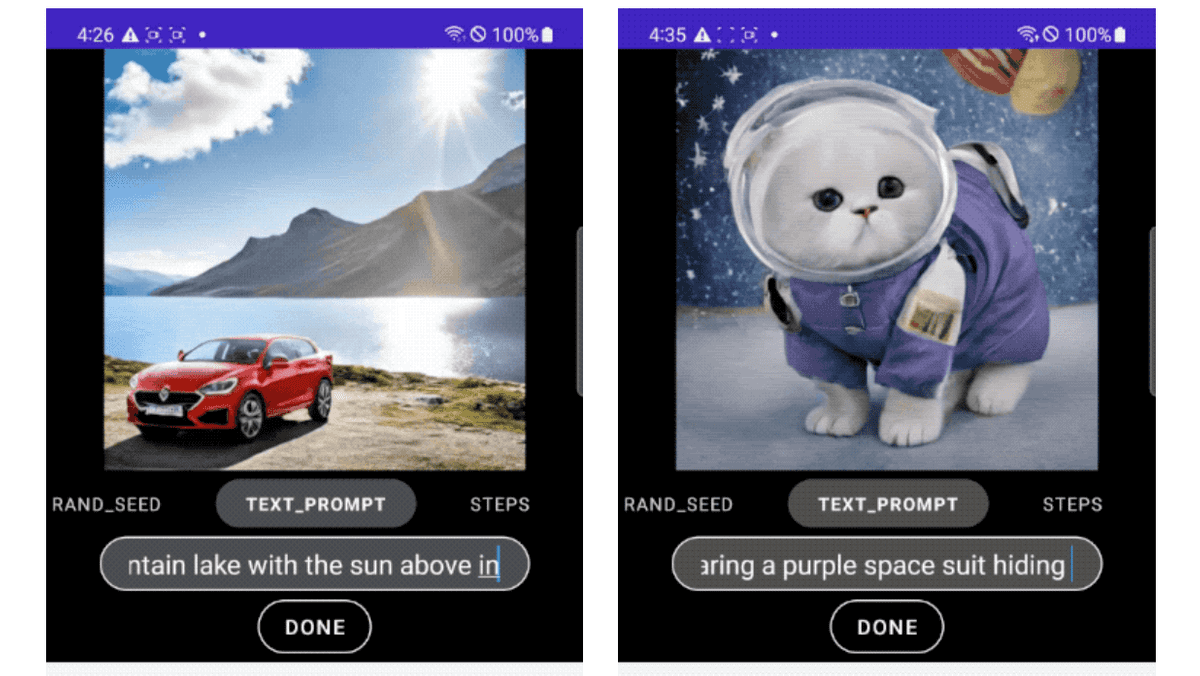
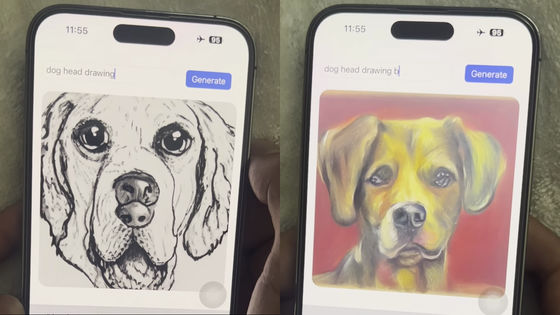
Click on the image below to see the image being generated in real time on your mobile device.

Google achieved one-step sampling by adopting
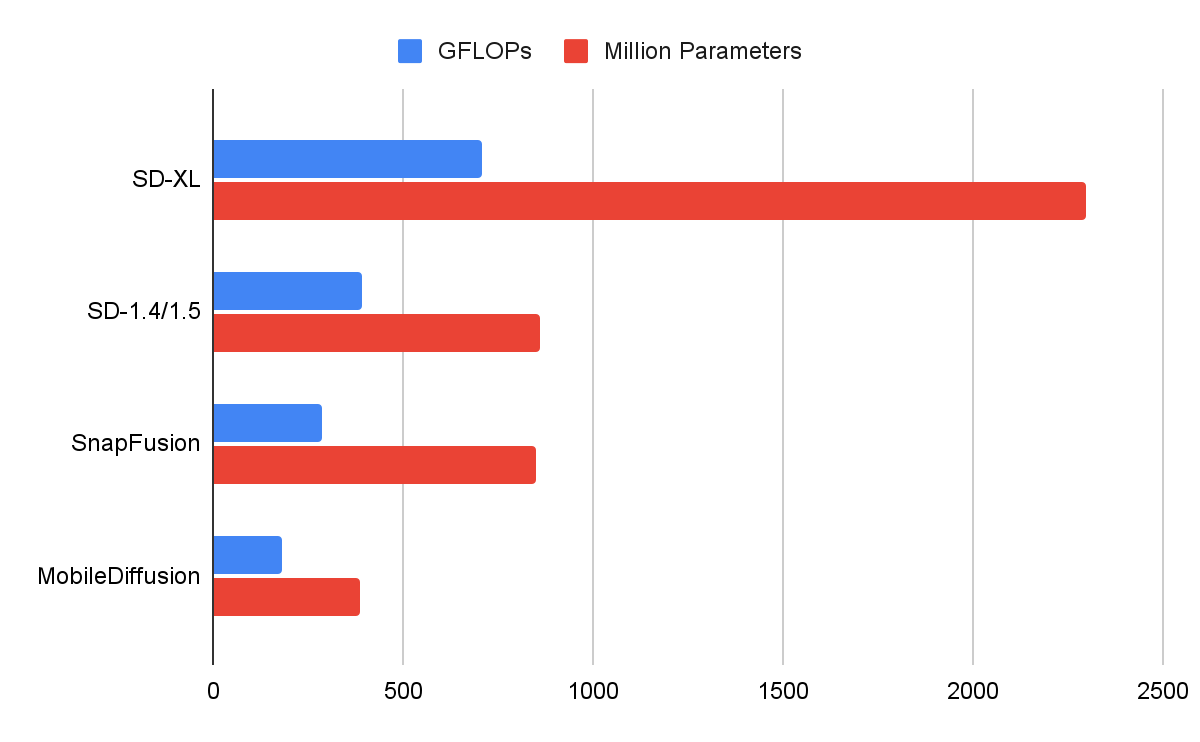
Comparing MobileDiffusion's UNet and some other diffusion model's UNet, the image below shows that MobileDiffusion has superior efficiency in terms of FLOPs (floating point operations) and number of parameters. In addition to UNet, Google has also optimized the image decoder, significantly improving performance and reducing latency by nearly 50%.
Below are images created with MobileDiffusion's ability to achieve DiffusionGAN's one-step sampling. In the end, the model had a compact number of 520 million parameters and was able to generate high quality and diverse images on mobile devices.

Related Posts:






in Software, Posted by log1p_kr