Google announces large-scale language model ``AudioPaLM'' that can translate from speech to ``both text and speech''

Google announced ' AudioPaLM '. AudioPaLM is a multi-modal architecture that integrates a text-based language model '
[2306.12925] AudioPaLM: A Large Language Model That Can Speak and Listen
https://doi.org/10.48550/arXiv.2306.12925
AudioPaLM
https://google-research.github.io/seanet/audiopalm/examples/

AudioPaLM processes and generates text and speech with a single model based on the function that stores paralinguistic information such as speaking speed, voice strength, pitch, silence, and intonation from AudioLM and the linguistic knowledge of PaLM 2. It is possible to
In the movie below, you can listen to the actual input voice (Original) and the voice translated into various languages with AudioPaLM (Translation with AudioPaLM).
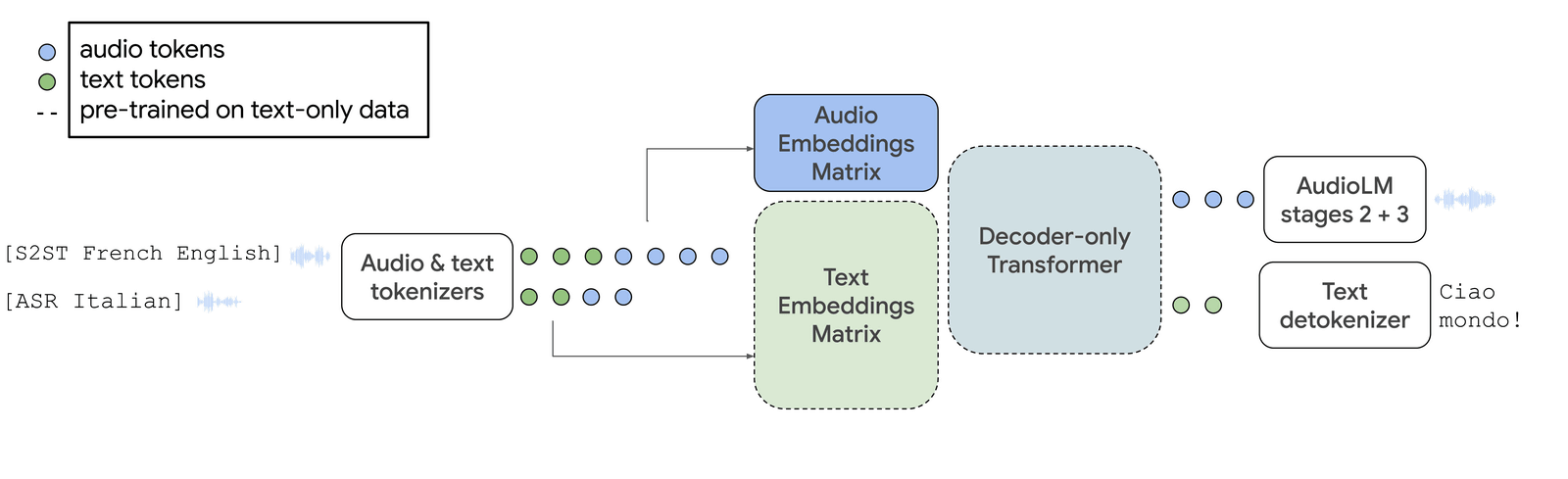
Below is a schematic diagram of AudioPaLM. Audio tokens and text tokens are generated at the same time from the audio input in 'Audio & text tokenizers', and converted to an audio embedding matrix (Audio Embeddings Matrix) and a text embedding matrix (Text Embeddings Matrix) respectively. Then, the voice token converted by the Decoder-only Transformer is 'AudioLM stages 2+3', the text token is processed by 'Text detokenizer', and the voice and text are output.
According to Google, audio processing has been improved by initializing AudioPaLM with PaLM 2 weights. From this, it became possible to support speech processing tasks by utilizing the large amount of text learning data used in pre-learning, and as a result, it seems that the performance of speech translation greatly exceeds that of existing systems. . In particular, Google reports that it has become possible to translate unknown voices and texts not found in previous learning data.
AudioPaLM's

In AudioPaLM, it is also possible to translate short audio data into another language with the same voice as the speaker. Currently, when dubbing and translating foreign movies into Japanese, Japanese-speaking voice actors do the dubbing, but if this AI model evolves, it is expected that the dialogue will be dubbed into Japanese by the voice of the actor himself. increase.
Related Posts: