"GQN" to generate a 3D model by guessing "invisible part" from visible information
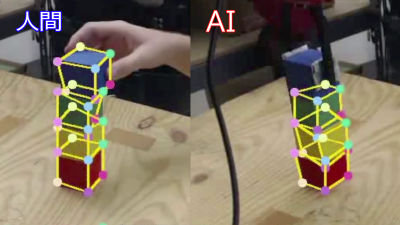
When a person confirms the existence of the table top plate and three legs with eyes, it guesses without permission in the head that "There is a fourth foot behind." Although such work is easy for human beings, it is said to be a very difficult task for artificial intelligence. Google's parent company Alphabet's affiliate AI companyDeep MindGuesses invisible parts from visible information "Generative Query Network (GQN)"Was developed.
Neural scene representation and rendering | Science
http://science.sciencemag.org/content/360/6394/1204.full
Neural scene representation and rendering | Deep Mind
https://deepmind.com/blog/neural-scene-representation/
GQN is to predict the shape and positional relationship of objects from the input image and generate 3D space. As for the mechanism of GQN, DeepMind explains in the following movie.
Generative Query Networks - YouTube
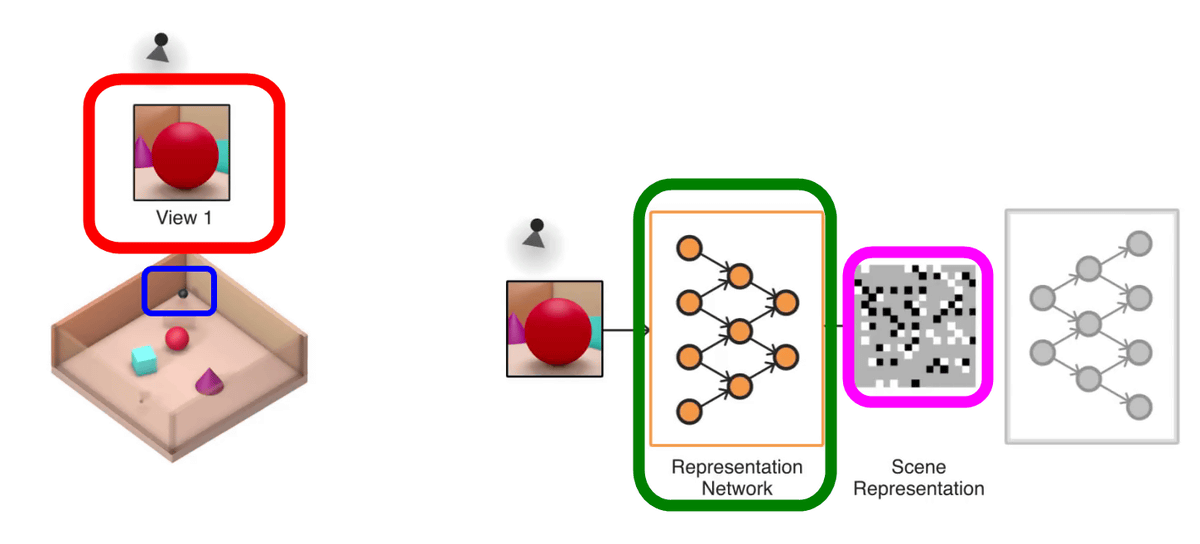
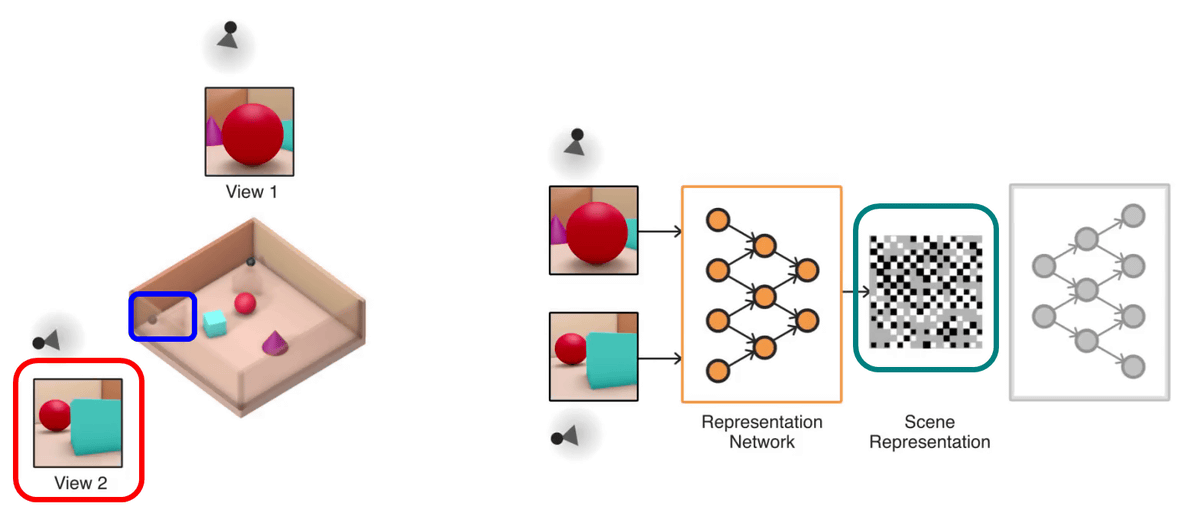
Here we prepare an actual model "in the red frame part of the image" red spheres surrounded by a wooden frame and turquoise blue cubes, three purple cones are arranged "actual model. For GQN, I will input only the images taken at two viewpoints on this model and try to guess the same 3D model as this model.

First, place the camera in the position where the red sphere looks like a red frame (blue frame) and take a picture. When you enter this image in GQN, the model is assembled with the green border Representation Network (Expression Network), and the model is analyzed with the Scene Representation (scene representation) of the pink frame. The gray part of "scene representation" shows the unknown part, and at this point you can see that the gray part occupies the majority. A 3D model generated by GQN can be generated from a single image, but if there are many unknown parts, the size of the object becomes oblong, the wall does not exist, etc., the model of the generated model It seems that the shape is not stable.
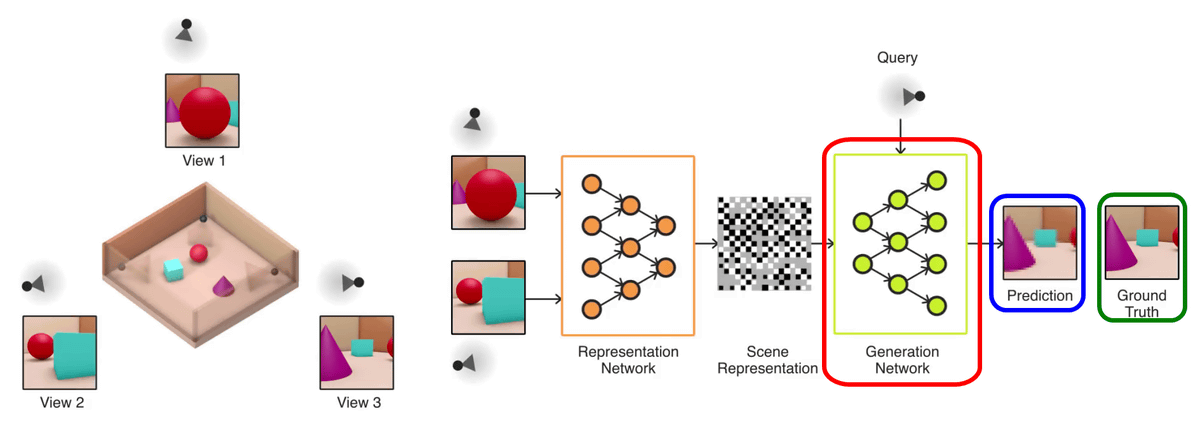
Next, arrange the blue frame camera so that the turquoise blue cube looks like a red frame, the red sphere is visible in the back, and let GQN read the image that can be seen from the camera. Then, as the information read by GQN increases, the number of gray parts indicating unknown parts decreases in the "frame representation" of the green frame.
Let us assume that GQN images (red frame) at the position where a purple cone comes in front, assuming that the camera is placed at the position of the blue frame.

Then, GQN creates a 3D model by Generation Network (generation network) based on information analyzed in "scene representation", and creates an image (blue frame) when the camera is placed at the specified position. Although the actual image is of the green frame, you can see that the same image is generated.
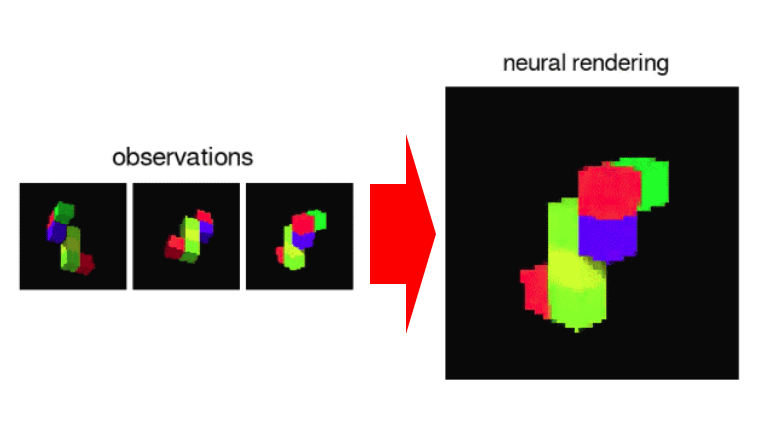
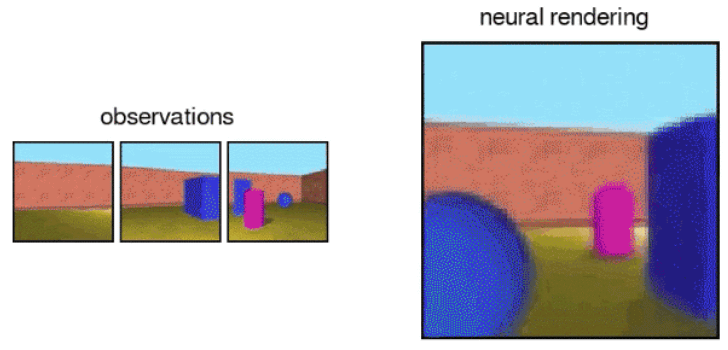
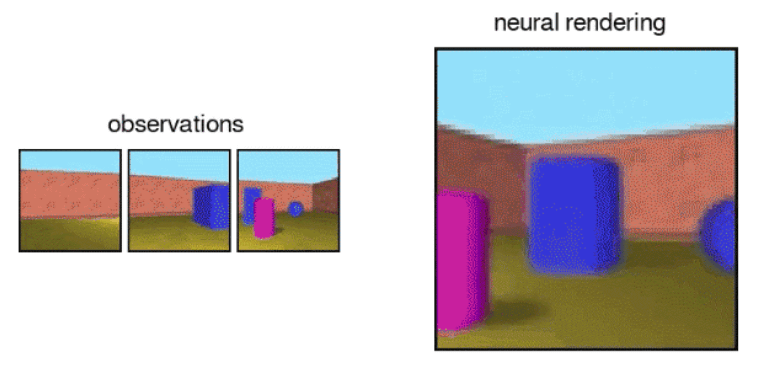
In addition to the specified viewpoint, you can see 3D space generated by GQN with your favorite viewpoint. For example, when an image in "observations" below is input, GQN creates predicted 3D space in "neural rendering" ...
FPSThe position of the viewpoint as if you are playing the gameseamlessIt is possible to change it.
According to DeepMind, GQN at the time of article creation can only create models with low resolution. However, due to future progress in hardware, it is said that GQN will be able to cope with even higher resolution models, and we are also considering application to VR and AR.
Related Posts: